How to Open Big CSV Files – an Ultimate Guide
TLDR; Opening a very large CSV file can strain typical software and hardware, but a variety of tools and techniques can help make the job easier. In our experience, some methods work far better depending on the dataset size. This guide walks through a variety of solutions from basic to advanced, beginning with spreadsheet-based approaches (like Excel’s Power Query and LibreOffice Calc), then looks at text editors such as EmEditor and UltraEdit for faster loading of big files. For more advanced needs, it covers using databases (SQLite, MySQL, PostgreSQL) to query large data efficiently. We also discuss command-line tools like CSVkit and xsv for speed, and even programming languages (Python, R) for maximum processing power. By comparing the strengths and limits of each option, you can pick the method that fits your needs best for opening and analyzing big CSV files.
Have you ever tried opening a large CSV file only to have your software crash or your computer freeze? Working with huge CSV files is challenging for a few reasons: many programs have built-in row or size limits, your computer’s RAM/CPU can get overwhelmed, and sometimes the sheer volume of data causes issues. For example, Microsoft Excel — a common first choice — has strict limits of 1,048,576 rows and 16,384 columns, making it unsuitable for larger datasets. In this guide, we’ll explore several effective ways you can open and work with large CSV files.
We’ve arranged the solutions roughly from the simplest to the most advanced, so you can jump in at whatever level suits your comfort. We'll start easy and move to more powerful (and sometimes trickier) tools. It's worth noting that while CSV is a common format, alternatives like TSV (Tab-Separated Values) and Excel’s XLS/XLSX formats are also widely used, and many tools in this guide can handle these formats as well.
Here we bring a detailed overview of the selected tools for handling large CSV files, which will be covered in detail in this post:
| Category | Tool | License / Free Version | Platform | Max Capacity (Size/Count) | Technical Expertise required | Resource Usage / Performance | Key Features | Limitations |
|---|---|---|---|---|---|---|---|---|
| Excel Alternatives | LibreOffice Calc | Open-source / Yes | Windows, macOS, Linux | ~1M+ rows | Low | Moderate RAM usage, better than Excel for large files | Performance decreases with very large datasets / Free alternative to Excel, handles slightly larger files | Slows with very large files |
| Power Query | Paid / No free version but available for free in Power BI Desktop | Windows, macOS | No specific row limit, but subject to available system resources (memory, CPU). | Low | High RAM usage, proportional to file size | Handles medium to large datasets / Familiar interface, advanced data import, handles larger files than Excel without Power Query | memory-intensive for large datasets | |
| Online CSV Tools | CSV Explorer | Free / Yes | Web | 5M rows | Low | Light resource usage | Efficient for moderate files up to 5 GB / Simple file upload, fast filtering, sorting, no installation needed | Internet required, lacks advanced data manipulation features |
| Zoho Sheet | Free / Yes | Web | Not specified explicitly | Low | Light resource usage | Slower with huge files, and limited advanced data manipulation. / Cloud-based, Excel compatibility, real-time collaboration. | Slower with very large files, lacks advanced data manipulation features. | |
| Google Sheets | Free / Yes | Web | 10M cells | Low | Depends on the browser | Slower with large files / Cloud-based, easy collaboration, no need to install | Slower with large files due to internet latency | |
| Text Editors | EmEditor | Paid license with Free trial / No | Windows | 16 TB | Low | Low to moderate RAM usage | Very fast even with extremely large files / Very fast with large files, CSV mode for tabular view | Paid license |
| UltraEdit | Paid / No | Windows, macOS, Linux | Multi-GB | Low | High RAM usage for very large files | Handles multi-GB files well / Some CSV editing features like column mode editing | Paid software, resource intensive for extremely large files | |
| Large Text File Viewer | Free / Yes | Windows | Multi-GB files | Low | Low resource usage | Fast viewing of large files without high memory usage / Quick viewing and searching of large CSV and text files | No CSV specific features and load CSV as text, Read-only, cannot edit or manipulate data | |
| Desktop Applications | Modern CSV | Paid / No (Free trial) | Windows, macOS, Linux | Multi-GB | Low to Medium | Efficient RAM usage, optimized for large files | Performs well with multi-GB datasets / Advanced CSV editing, fast performance with large files | Paid license required for continued use |
| OpenRefine | Open-source / Yes | Windows, macOS, Linux | Medium to large files | Medium | Moderate RAM usage, depending on data size | not optimized for extremely large datasets / Powerful data cleaning and transformation, open-source | Steeper learning curve for beginners | |
| Tad Viewer | Free / Yes | Windows, macOS, Linux | Multi-GB | Low | Low resource usage, handles large files efficiently | Very fast for viewing large files / Simple CSV viewer, lightweight, fast with large files | Read-only, lacks editing features | |
| Command-Line Tools | CSVkit | Open-source / Yes | Windows, macOS, Linux | Medium to large files | High (CLI skills) | Low resource usage, efficient with large files | Performs well with medium to large files / Suite of CSV utilities, SQL-like querying, powerful for data filtering and manipulation | Not optimized for extremely large files |
| AWK, sed, grep | Open-source / Yes | Unix/Linux, macOS, Windows (with compatibility layers) | Very large files | High (CLI and scripting skills) | Low resource usage, efficient line-by-line processing | High performance due to streaming capability / Powerful text processing, pattern matching, substitution, stream editing | Not optimized for complex CSV parsing, advanced scripting required for complex tasks | |
| xsv | Open-source / Yes | Windows, macOS, Linux | Multi-GB | High (CLI skills) | Low resource usage, very efficient for large files | Performs well with large datasets due to streaming capability / High-speed CSV processing, supports streaming data, lightweight | Limited advanced features, less user-friendly than GUI tools | |
| Databases | SQLite | Open-source / Yes | Windows, macOS, Linux | Large datasets | Medium (SQL knowledge) | Low resource usage, handles large datasets efficiently | Solid performance with large datasets in read-heavy operations / Lightweight, file-based database, easy setup, supports SQL querying | Limited concurrency, not ideal for write-heavy operations |
| MySQL | Open-source / Yes | Windows, macOS, Linux | Very large datasets (TBs) | High (Database admin skills) | Requires more RAM/CPU for large queries | Solid performance for bulk data imports, scalable / Scalable, fast bulk data imports, SQL querying | Requires setup and server management, more complex for beginners | |
| PostgreSQL | Open-source / Yes | Windows, macOS, Linux | Very large datasets (TBs) | High (Database admin skills) | High resource usage for complex queries | Solid performance on massive datasets, fast bulk imports / Fast imports, flexible SQL querying, handles huge datasets efficiently | Requires setup and server management, steep learning curve | |
| Programming Languages | Python | Open-source / Yes | Windows, macOS, Linux | Larger-than-memory | High (Programming skills) | High memory usage for Pandas, better with Dask | Efficient with smaller datasets, Dask scales for large datasets / Extremely flexible, parallel computing with Dask, supports chunked file reading for large datasets | Requires coding knowledge, memory issues with large datasets unless using optimized libraries like Dask |
| R | Open-source / Yes | Windows, macOS, Linux | Multi-GB | High (Programming skills) | Moderate RAM usage, efficient for large datasets | High-performance for large datasets / High-performance data manipulation, memory efficient with large datasets | Learning curve, memory limitations for datasets larger than available RAM unless optimized |
Challenges When Opening Large CSV Files
Working with large CSV files can be challenging. Data can grow rapidly when exporting full databases or detailed records, such as logs or transactions. The more comprehensive the dataset, the bigger the file, and that’s when the real challenges start to surface.
Avoiding these problems requires the right tools and strategies, but understanding the common pitfalls is the first step to ensuring the smooth handling of large CSV files.
- Software Limitations: Tools like Excel have a hard row limit — Excel’s cap is 1,048,576 rows — and attempting to open files exceeding this limit can cause the software to become unresponsive, or only load a portion of the data without warning.
- Hardware Constraints: Big files will hammer your RAM and CPU — expect slowdowns.
- Data Integrity Risks: When software crashes mid-process, you risk data loss, and some programs might even truncate the file without warning.
Additionally, complex columns, such as JSON embedded in a CSV cell, can lead to several common parsing issues:
- Incorrect Delimiter Detection: Programs can sometimes misinterpret the delimiter, for instance, when quotes are used within cell values.
- Multiline Records: Fields that contain newlines can throw off parsers, leading to errors in reading the file.
- Encoding Problems: Differences in character encoding can cause import issues, especially when handling data from diverse sources.
Choosing Best Tool for Large CSV Files
Now that we’ve examined why CSV files become large and the challenges they pose, let's focus on how to choose the right tool to handle them effectively.
- Performance and Speed: Handling large files efficiently without excessive resource consumption.
- Ease of Use: User-friendly interfaces and minimal learning curves.
- Cost: Availability of free or open source solutions versus paid solutions.
- Platform Availability: Windows, macOS, Linux platforms, or Web-based.
- Features: Advanced data manipulation, filtering, and analysis capabilities.
- Scalability: Capable of efficiently opening and processing CSV files ranging from gigabytes to terabytes.
If you want to try out the methods mentioned in this guide for handling large CSV files, here are some publicly available datasets to practice with:
- NYC Taxi Trip Data
- US Census Bureau Data
- COVID-19 Open Data
- Kaggle Datasets
- IMDB 5000 Movie Dataset You can also explore more options in our previous blog post on available datasets.
Below, we’ve categorized the best tools code-based and non-code-based to help you work with large CSV files, regardless of your technical expertise.
I. Excel Alternatives
In this section, we detail the top spreadsheet-based methods for managing large CSV files effectively.
A. LibreOffice Calc
LibreOffice Calc is a free, open-source alternative to Excel that can handle large files more efficiently.
Step-by-Step Guide:
-
Download: Get LibreOffice from its official website and launch it on your computer.
-
Import CSV: Go to 'File > Open', select your CSV file, and click 'Open'.
-
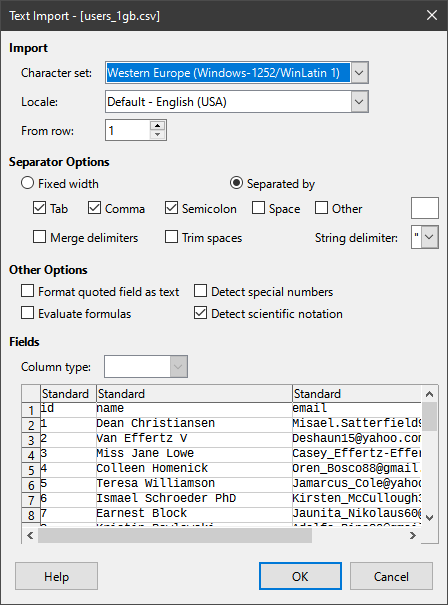
Set Import Options: If it looks weird, double-check the delimiter settings.
-
Edit Data: Your data is now editable in Calc.
The CSV files used in the tools and guides were generated using the Faker library.
To improve performance, you can adjust memory settings under 'Tools > Options > LibreOffice > Memory'. While LibreOffice Calc handles up to a million rows, it struggles with multi-gigabyte files and can become unresponsive, unlike Excel's Power Query, which we will explore in the next section.
B. Power Query
Using Power Query, you can import large CSV files more efficiently than Excel itself. It bypasses the 1 million row limit by loading data into the Data Model, making it faster and more capable.
Step-by-Step Guide:
-
Getting Started: Get Excel from its official website and launch it on your computer.
-
Access Power Query: Navigate to the 'Data' tab on the ribbon.
-
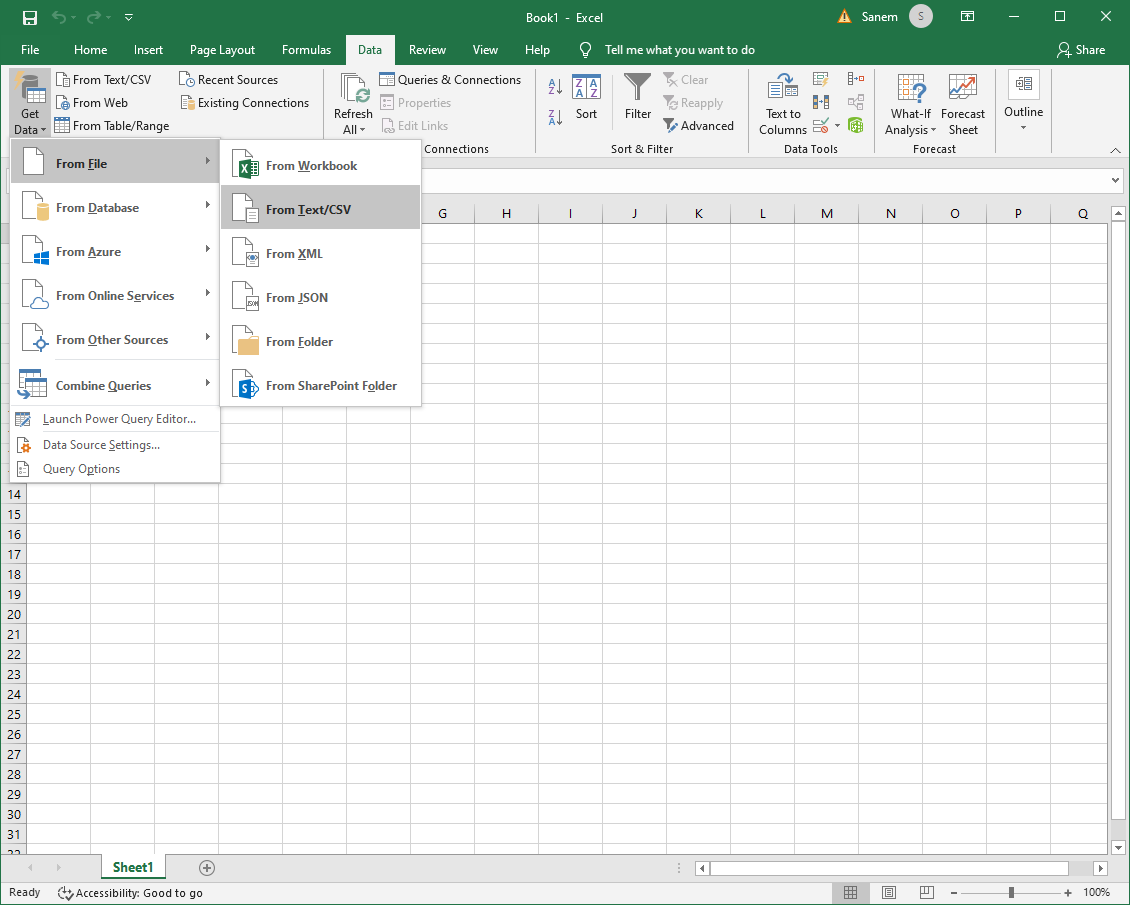
Import Data: Click on 'Get Data > From File > From Text/CSV'.
-
Select Your CSV File: Browse to your CSV file, select it, and click 'Import'. After selecting your file, you’ll see the following window:
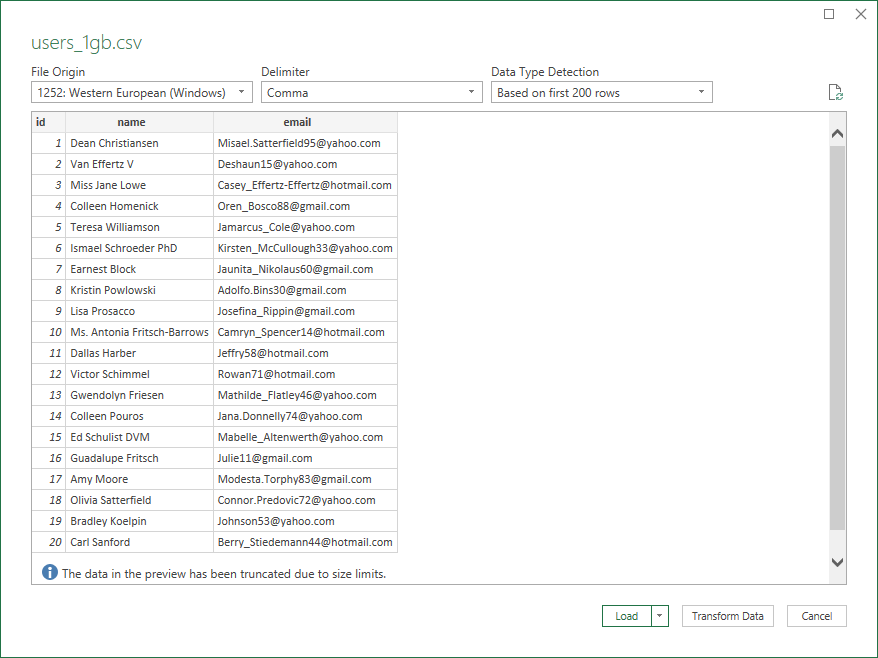
-
Preview and Transform Data: Excel will load a preview of the data. Click 'Transform Data' to open the Power Query Editor.
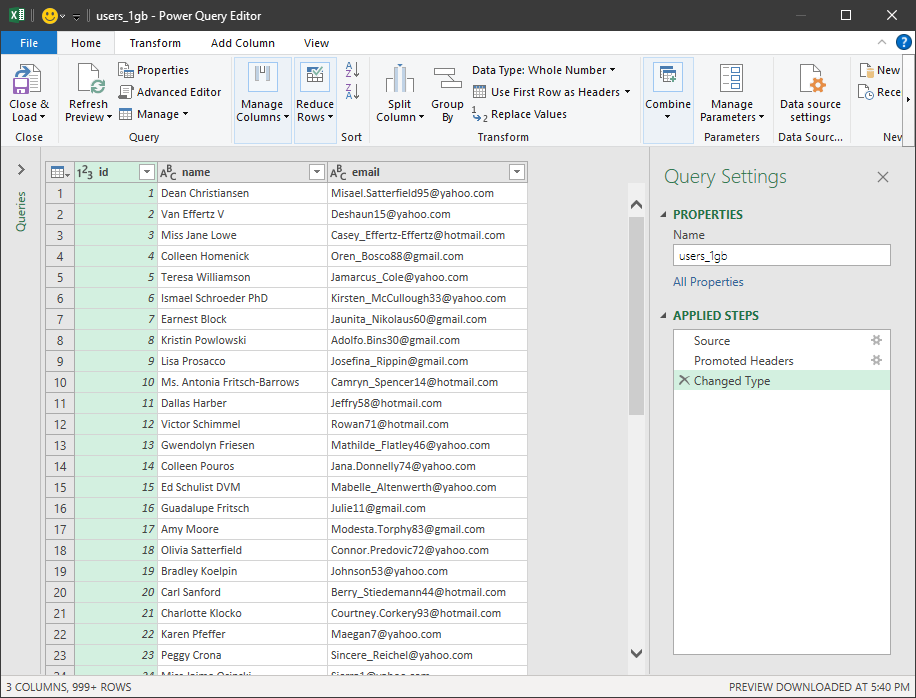
-
To improve performance, disable automatic data type detection in the Power Query Editor:
-
In the Power Query Editor, go to 'File > Options and Settings > Query Options'.
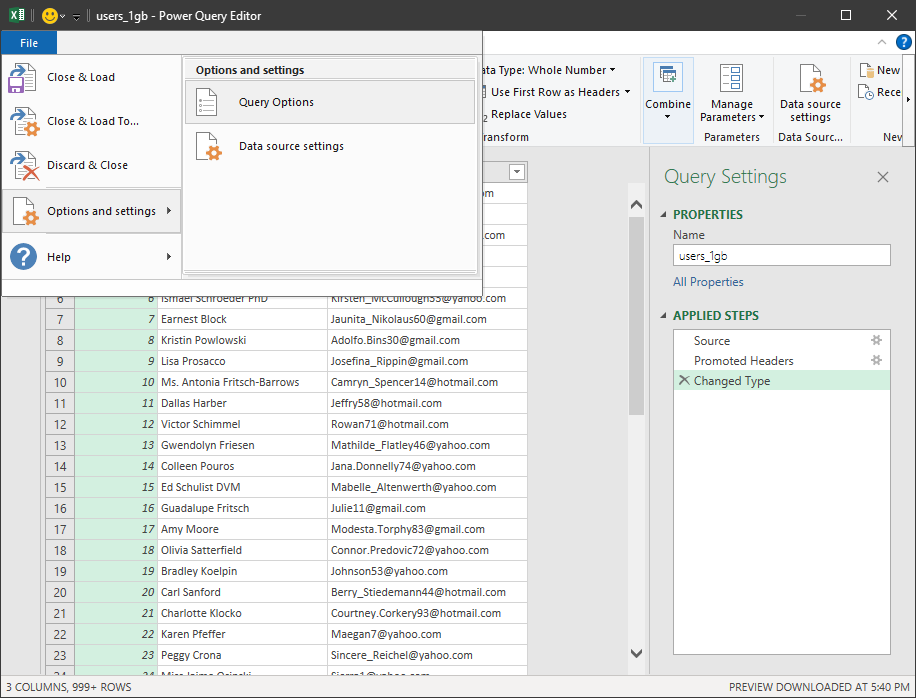
-
Under 'Global > Data Load', uncheck 'Detect column types and headers for unstructured sources'.
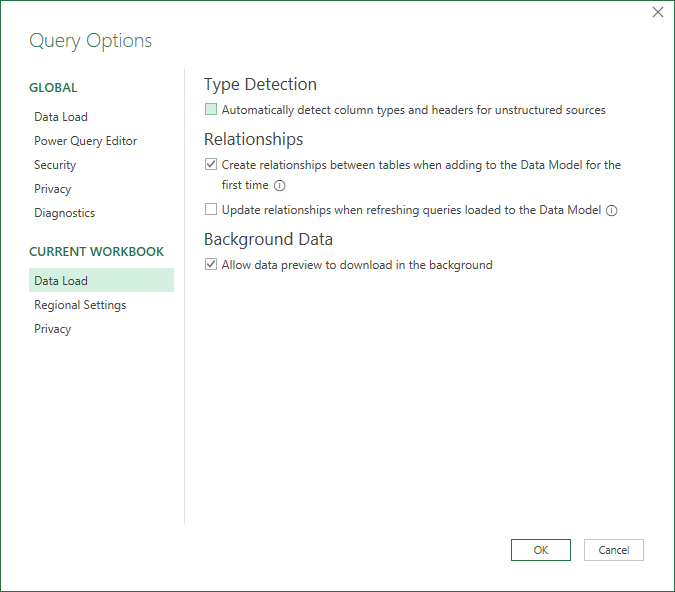
-
-
Load to Data Model:
-
Click on 'Close & Load To...' in the Home tab.
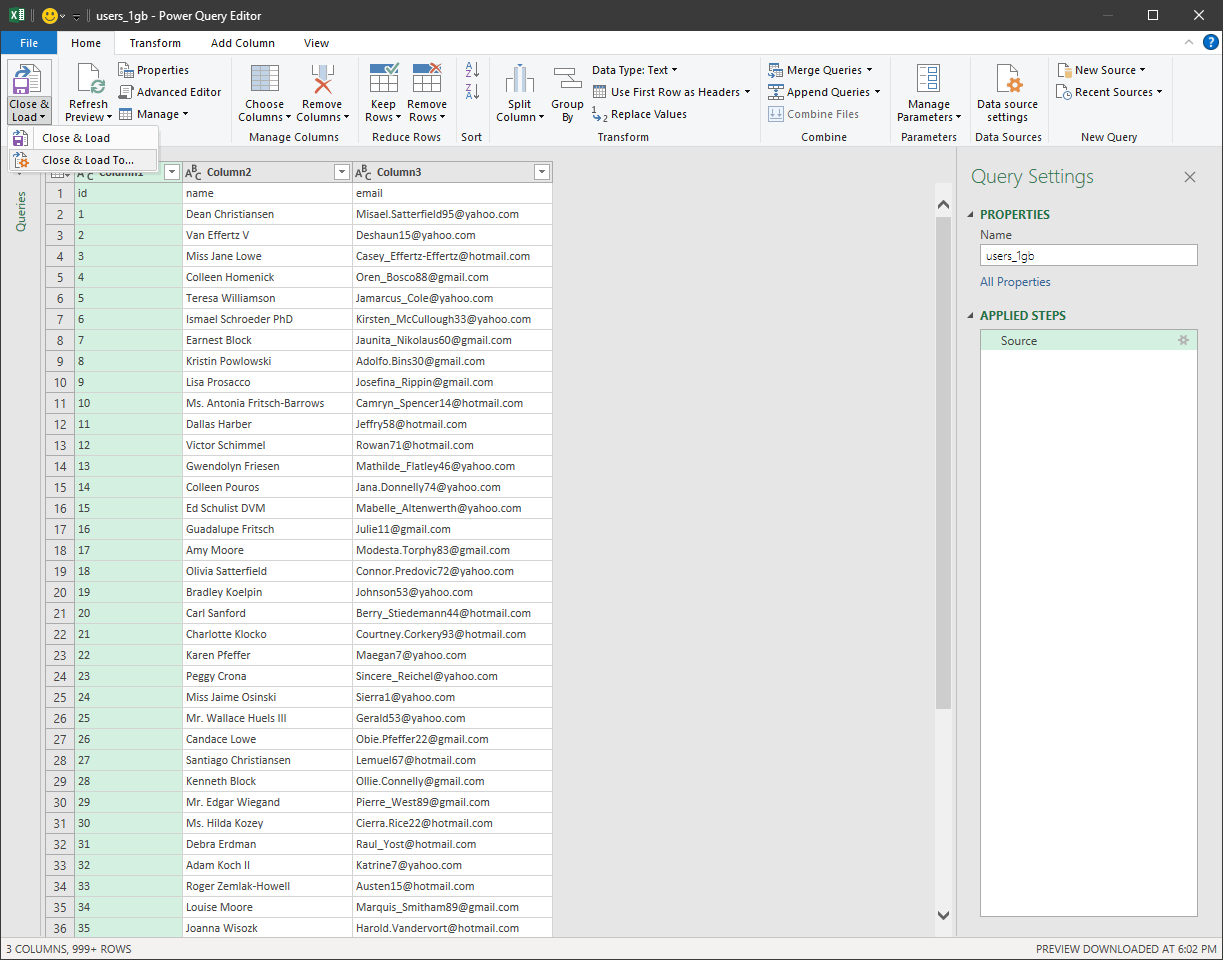
-
In the import dialog, select 'Only Create Connection' and check 'Add this data to the Data Model'.
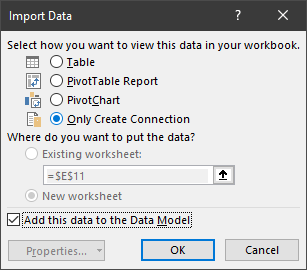
-
-
Work with Your Data: You can use PivotTables or Power Pivot to analyze data from the Data Model without loading it into the worksheet grid.
Save often, as large operations can still crash Excel. Even with Power Query, Excel relies heavily on RAM, so handling multi-million-row datasets can lead to slowdowns, freezing, or crashes, especially during complex tasks.
While spreadsheet software applications are user-friendly, they struggle with large datasets, often leading to slowdowns or crashes. For better performance with bigger CSV files, let’s explore advanced tools next.
II. Online Tools
Online tools offer a simple, convenient way to handle medium to large CSV files without installing extra software on your local machine. They're great for quick data checks, collaboration, and working across devices seamlessly.
A. CSV Explorer
CSV Explorer is a user-friendly online tool designed to easily upload and manage large CSV files. It offers key features like filtering, sorting, and basic data visualization, allowing you to analyze and explore datasets all in the browser.
Step-by-Step Guide:
-
Getting Started: Go to csvexplorer.com in your browser and sign up to start using the tool.
-
Upload Your CSV File:
-
Click on the 'Import Data' button.
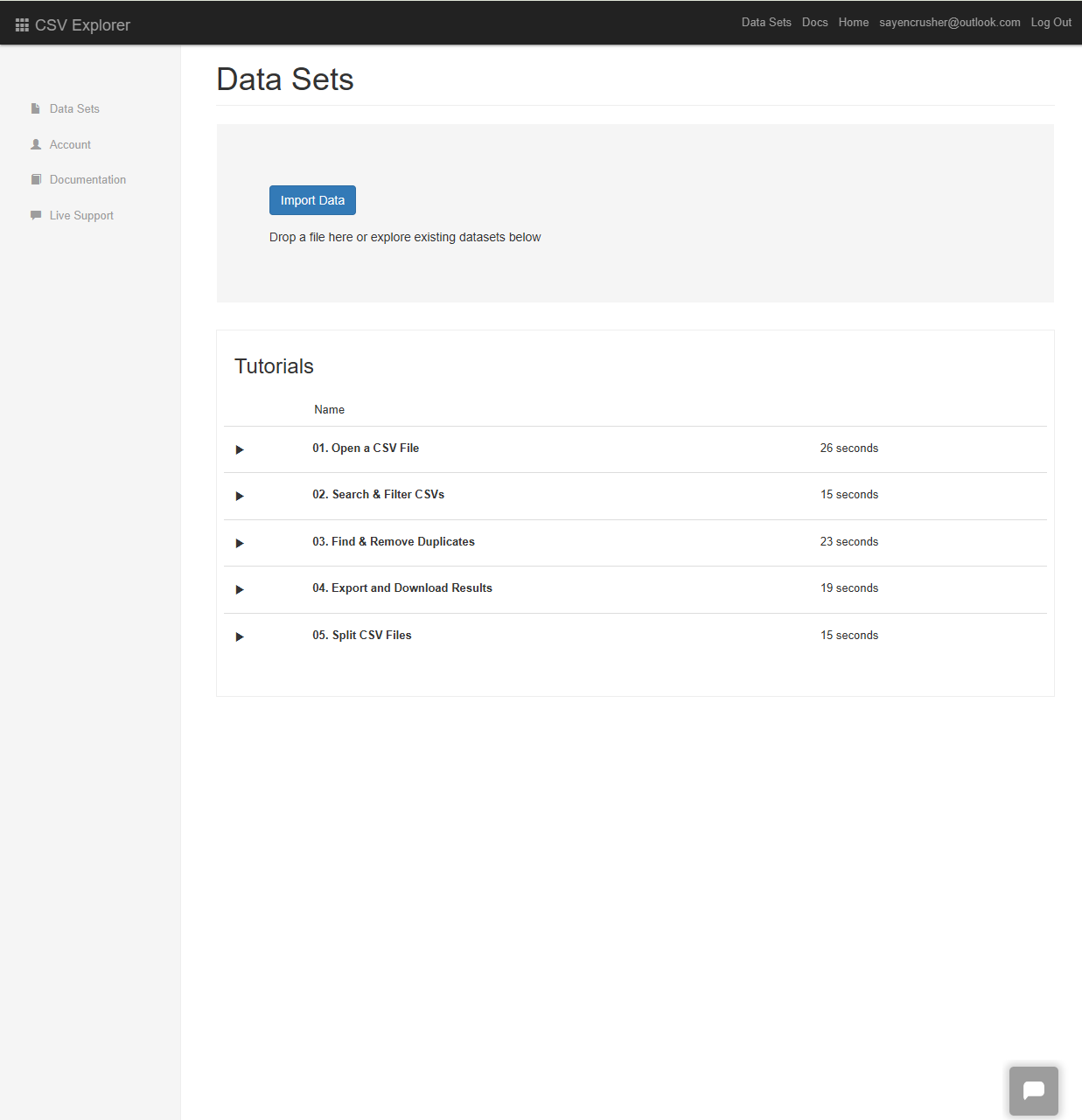
-
Click on the 'Choose File' option and select your CSV file from your computer, Google Drive, Box, or URL.
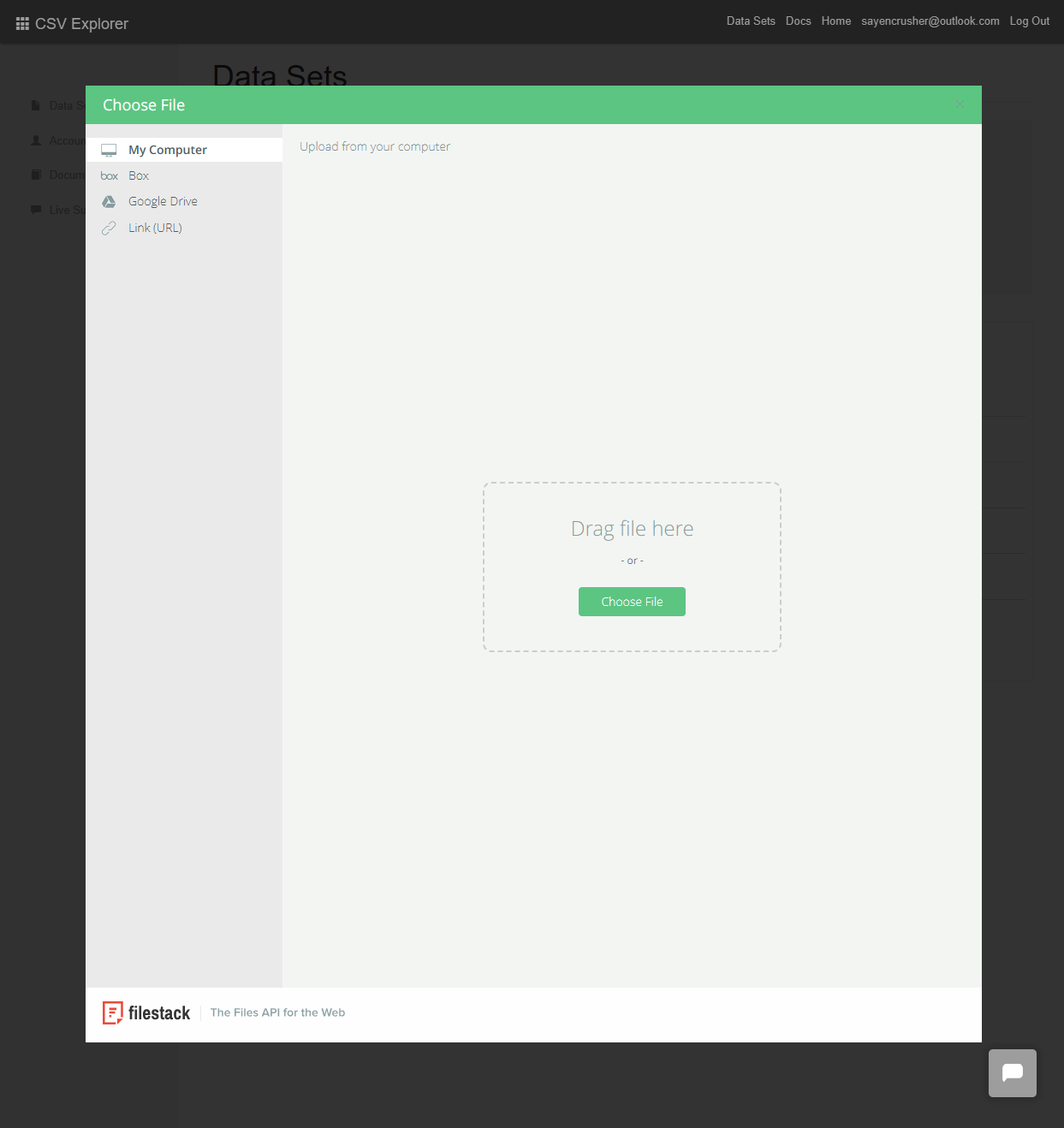
-
-
Open imported CSV file: In the list shown beneath 'Datasets', click to open and view your imported CSV file:
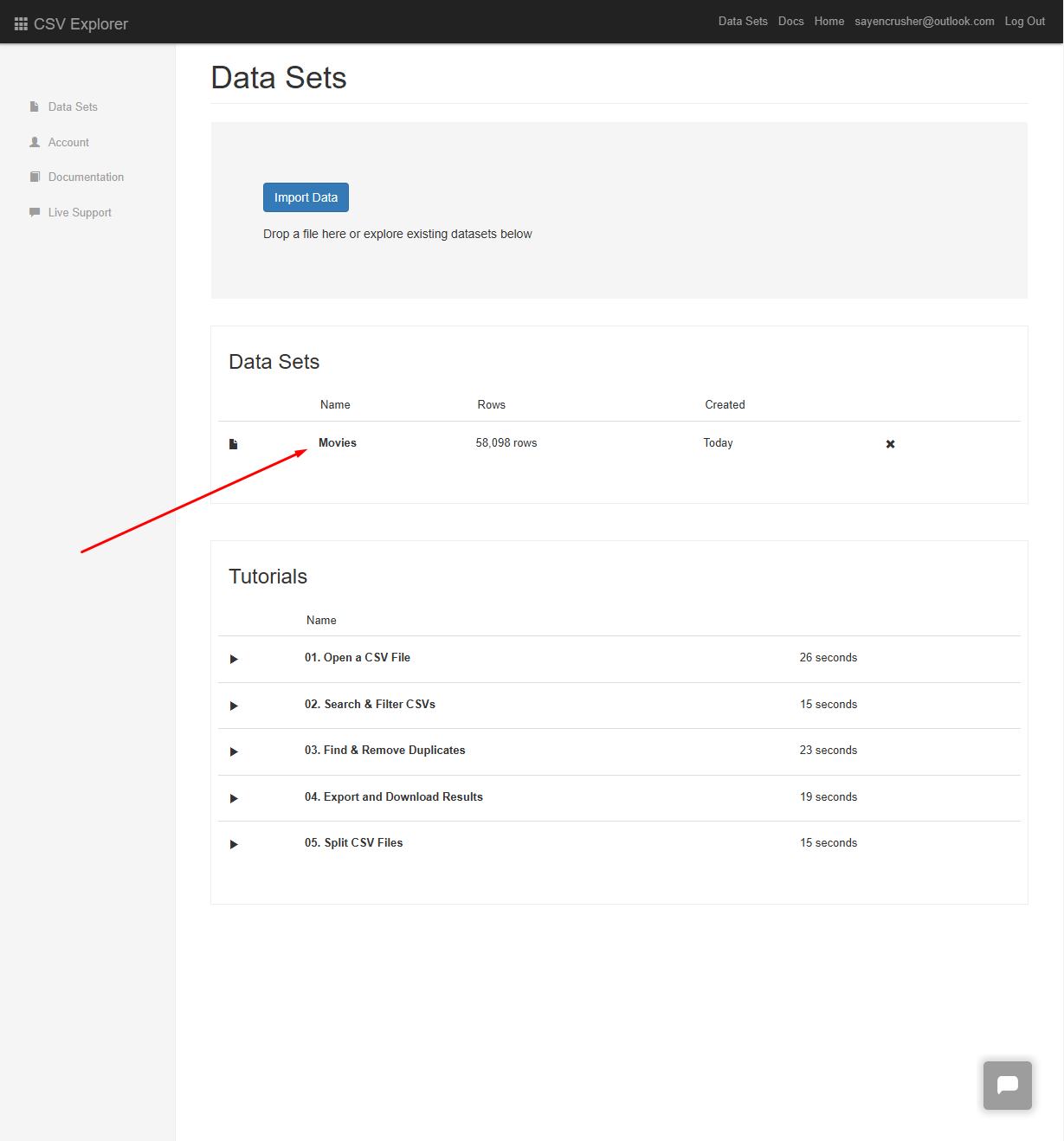
-
Work with your CSV file: After opening the CSV data, the sidebar options show that tasks like 'Search', 'Sort', 'Create Histogram', 'Download', and 'Split and Download' can be done.
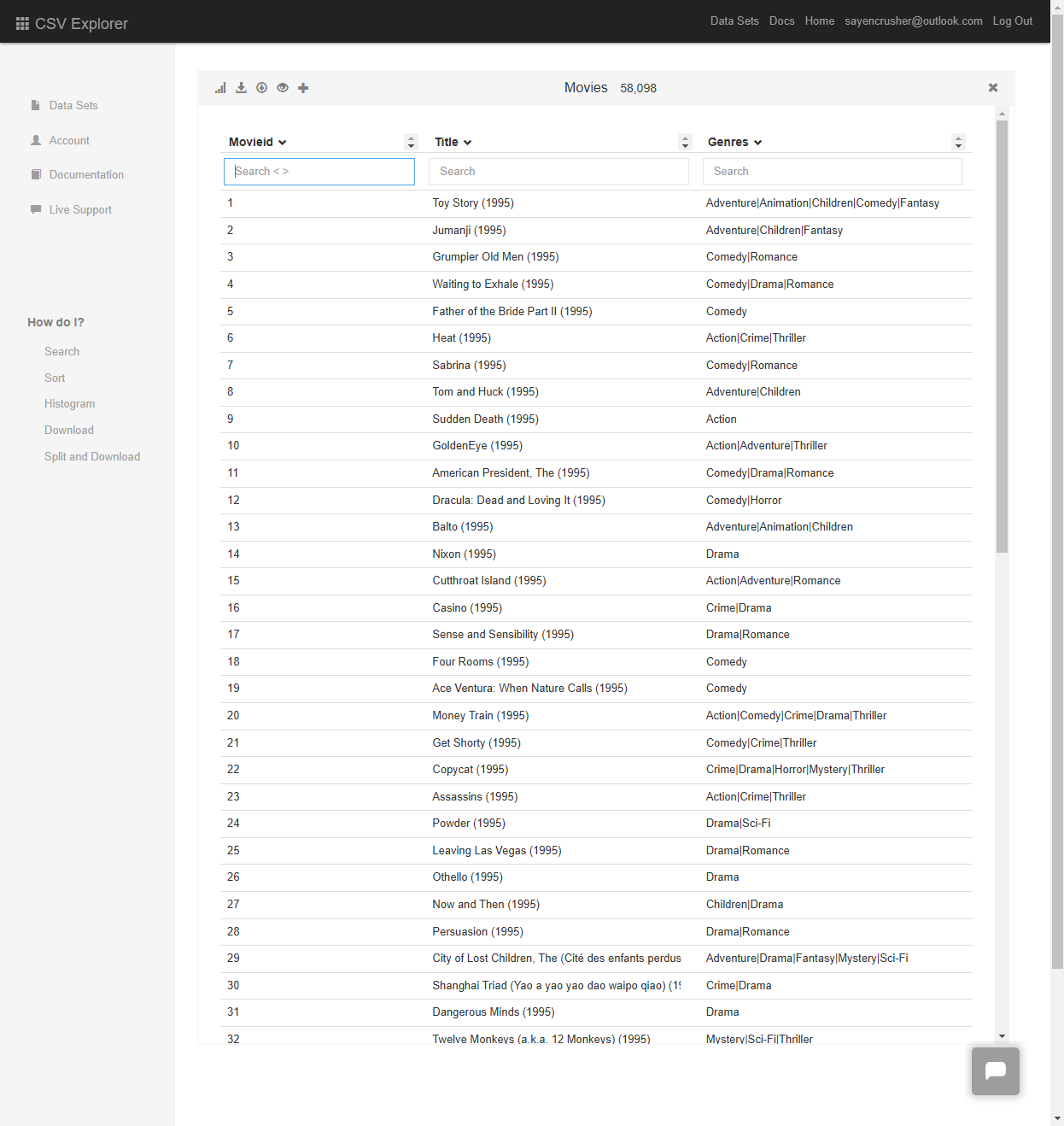
However, CSV Explorer also has limitations, such as a 5 million row cap and fewer advanced data manipulation features compared to desktop tools. While it's great for quick data checks and basic tasks, more complex analysis might require additional solutions.
B. Zoho sheet
Zoho Sheet is a versatile online tool that lets you easily manage large CSV files, with key features like real-time collaboration, cloud storage, and seamless Excel compatibility. Its data analysis tools, including formulas and pivot tables, make it ideal for team projects and basic data processing.
Step-by-Step Guide:
-
Getting Started: Go to the Zoho Sheet website in your browser and sign up to start using the tool.
-
Create a New Spreadsheet: Click on 'New Spreadsheet' or 'Upload' to import your CSV file.
-
Upload Your CSV File: In the 'Upload' dialog, select your CSV file, then choose the appropriate settings for delimiters and other settings:
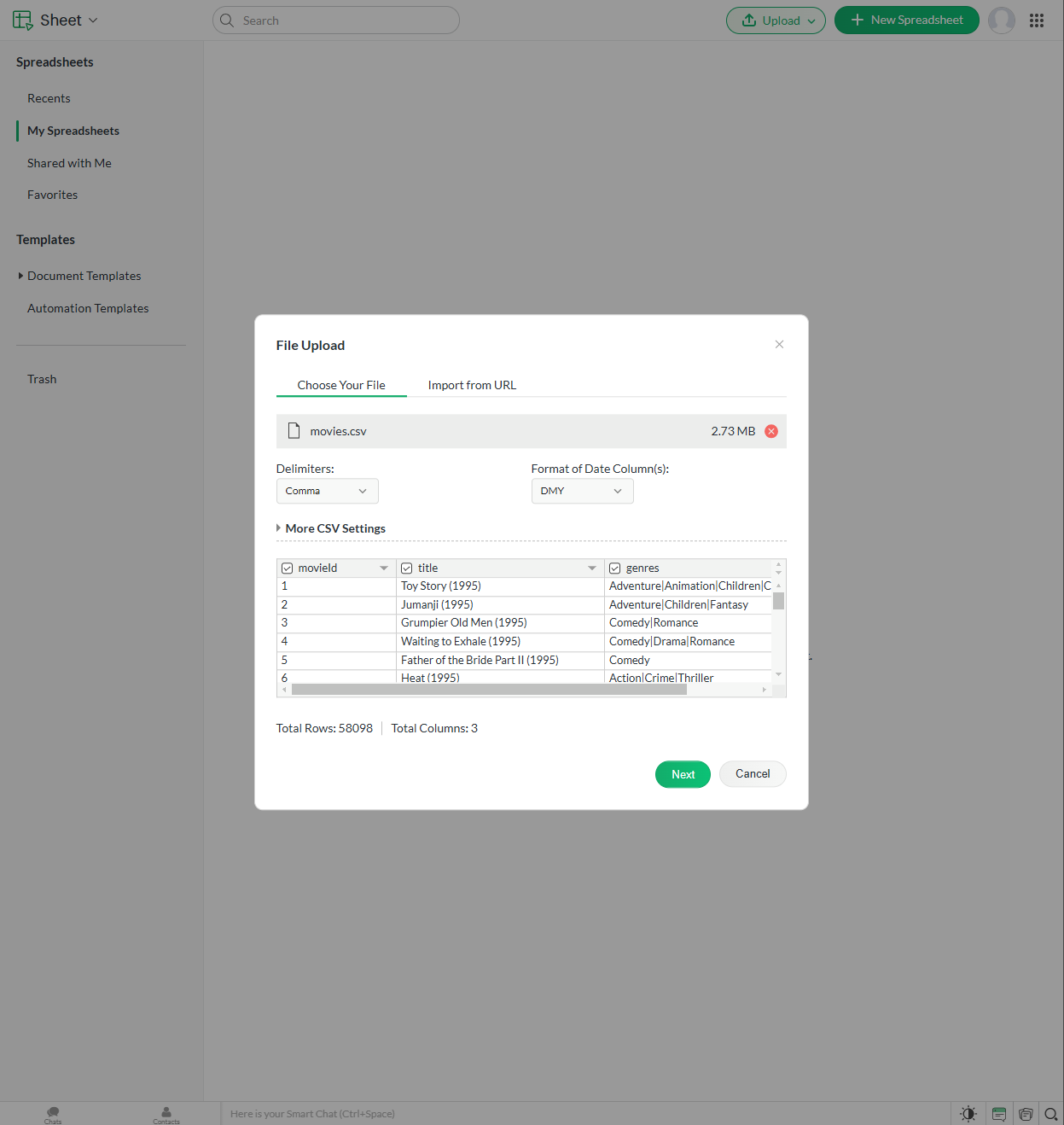
-
View and Edit Data: Your CSV data will be displayed in spreadsheet format, then you can use standard spreadsheet functions to analyze your data.
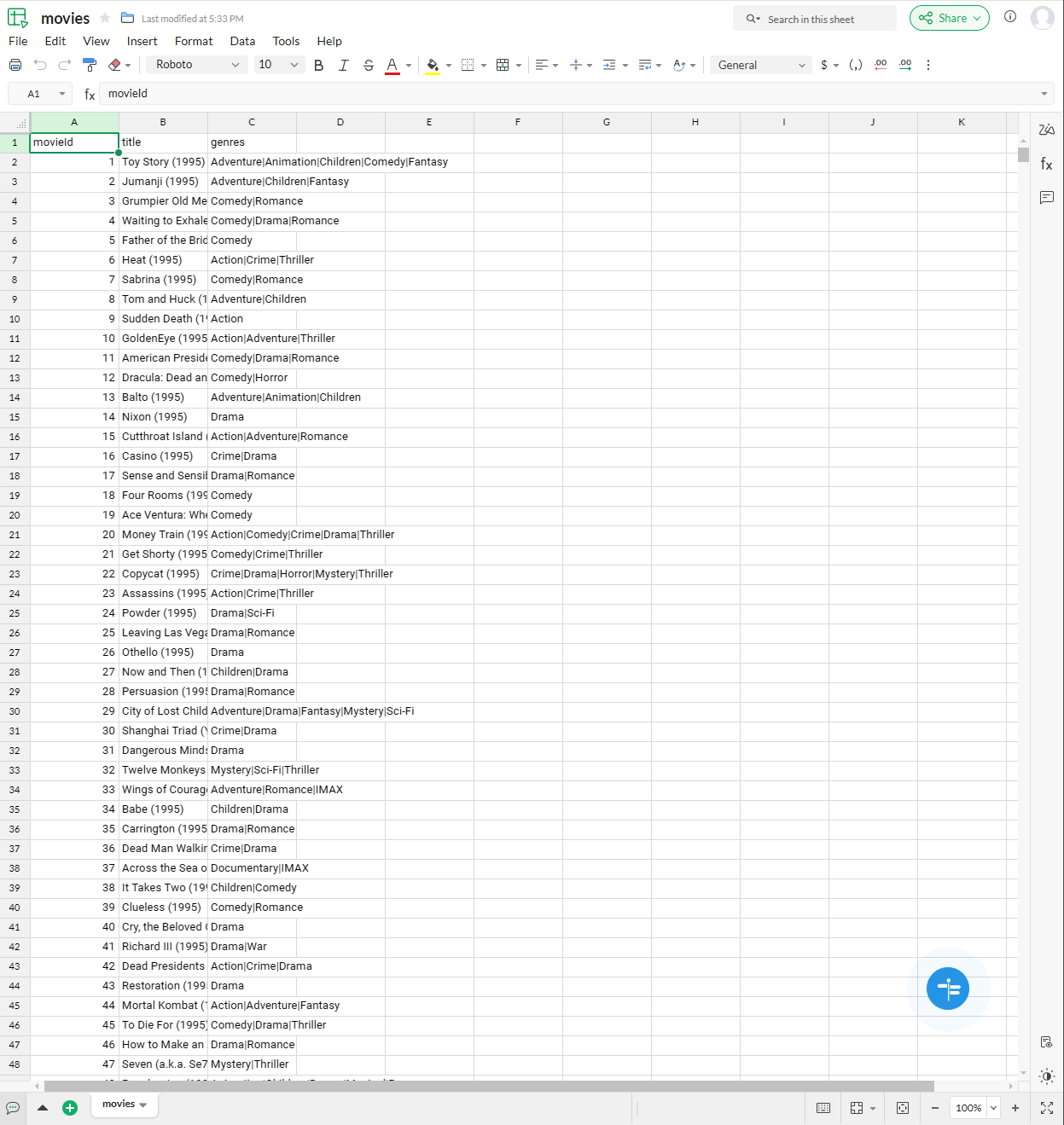
-
Collaborate with Others: Share the spreadsheet with team members for real-time collaboration.
-
Save and Export: Zoho Sheet automatically saves your work in the cloud. And, you can Export your spreadsheet in various formats if needed.
When using Zoho Sheet, uploads can get slow if your internet isn’t great. Besides, it lacks some advanced features found in desktop applications. For heavy data tasks, you might need more robust tools to avoid performance issues.
C. Google Sheets
Google Sheets is an online spreadsheet tool that can handle up to 10 million cells.
Step-by-Step Guide:
-
Getting Started: Go to Google Sheets and sign in with your Google account.
-
Import the CSV File: Click on 'Blank' to create a new spreadsheet, then go to 'File > Import'.
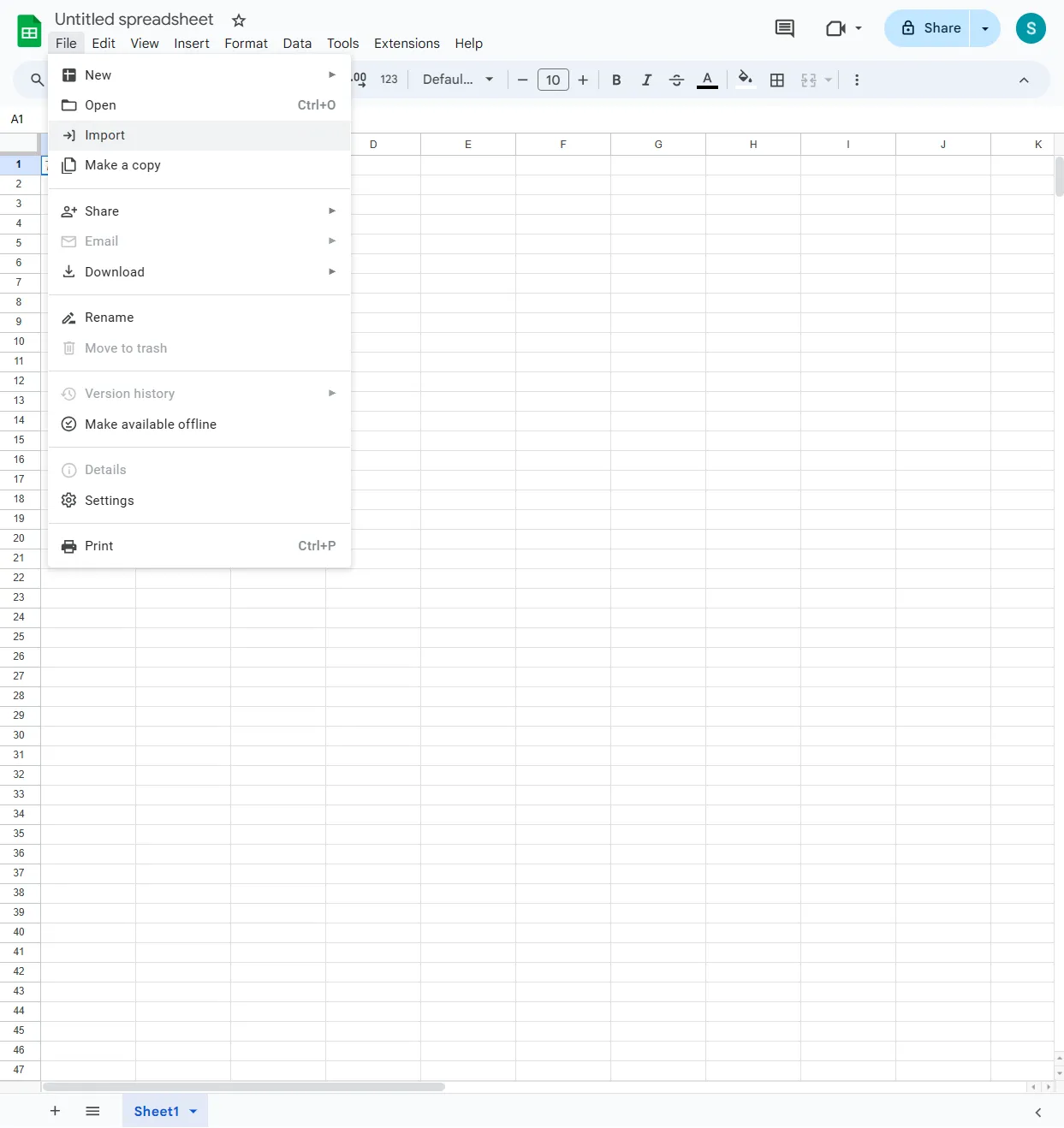
-
Upload Your File: In the Import file window, click on the 'Upload' tab, Drag and drop your CSV file, or click 'Select a file from your device'.
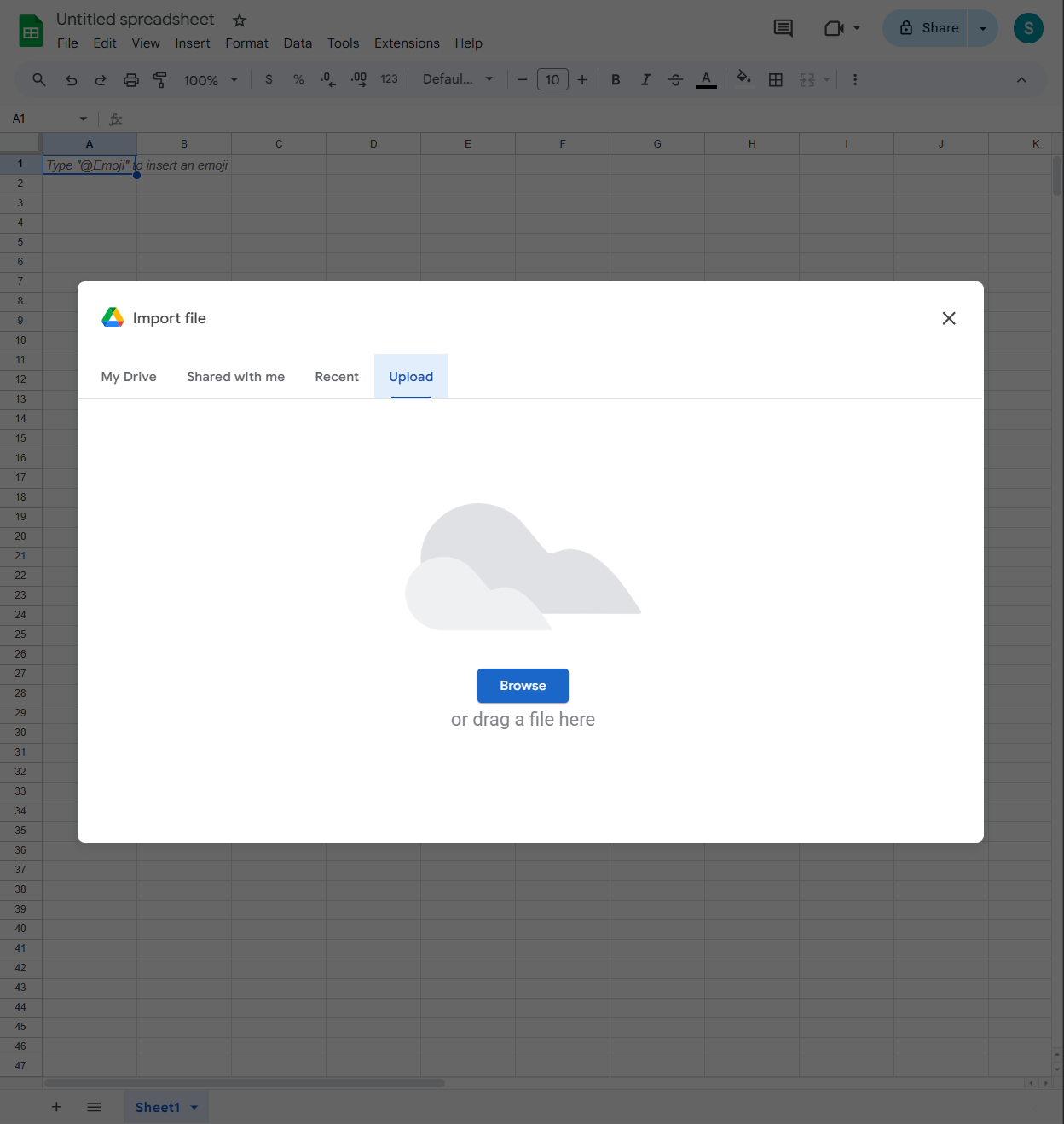
-
Configure Import Settings: Choose 'Replace spreadsheet' to overwrite the current sheet, and select the appropriate separator type (Comma for CSV), then click 'Import Data'.
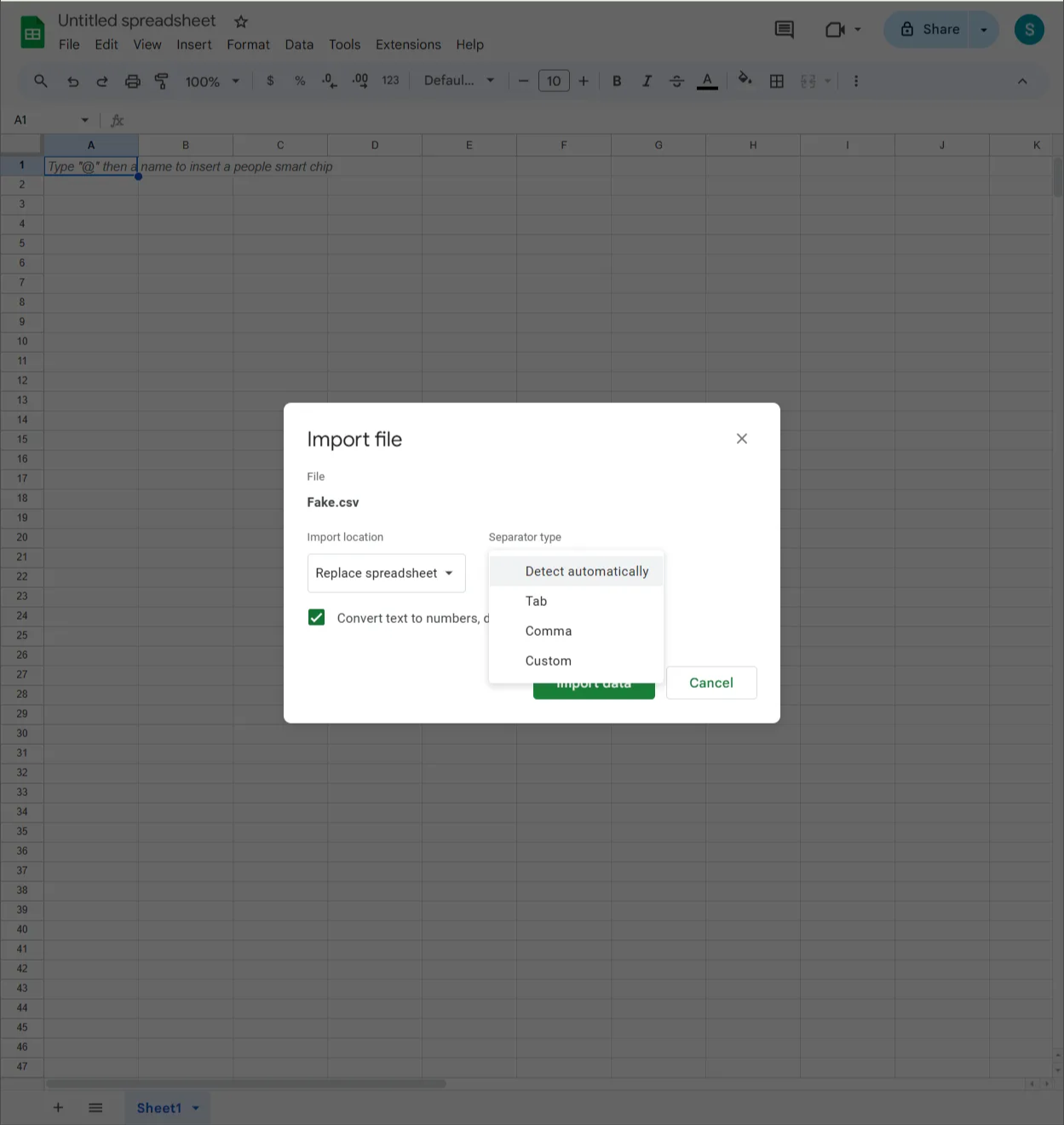
While Google Sheets supports up to 10 million cells, it often struggles with large datasets in practice. Cloud-based processing can cause delays in loading and editing, and browser limitations often lead to inconsistent performance or timeouts when working with big files.
Online tools are convenient but need stable internet and are limited by bandwidth and browsers. Next, we’ll explore offline options that overcome these constraints.
In the next sections (III. Text Editors and IV. Desktop Applications), the step-by-step instructions use the Windows versions of each application. Most of these tools are also available for macOS or Linux. You can check the overview table at the beginning of the post to see availability for your platform or visit the official site of each application.
III. Text Editors
A. EmEditor
EmEditor is an extremely fast text editor. it can open files up to 16 TB in size. It also has a special CSV mode designed for large files. With EmEditor, you can easily switch delimiters (e.g., comma vs. tab), freeze header rows for easier scrolling, and generally navigate huge tables with ease. It even includes advanced functions like pivot table generation, joining datasets, and flexible column manipulations. In short, EmEditor works well not only for basic viewing/editing of large CSVs, but also for more complex data cleanup tasks.
Step-by-Step Guide:
-
Getting Started: Get EmEditor from its official website and launch it on your computer.
-
Open Your Large CSV File: Launch EmEditor. Go to 'File > Open' or drag and drop your CSV file into EmEditor.
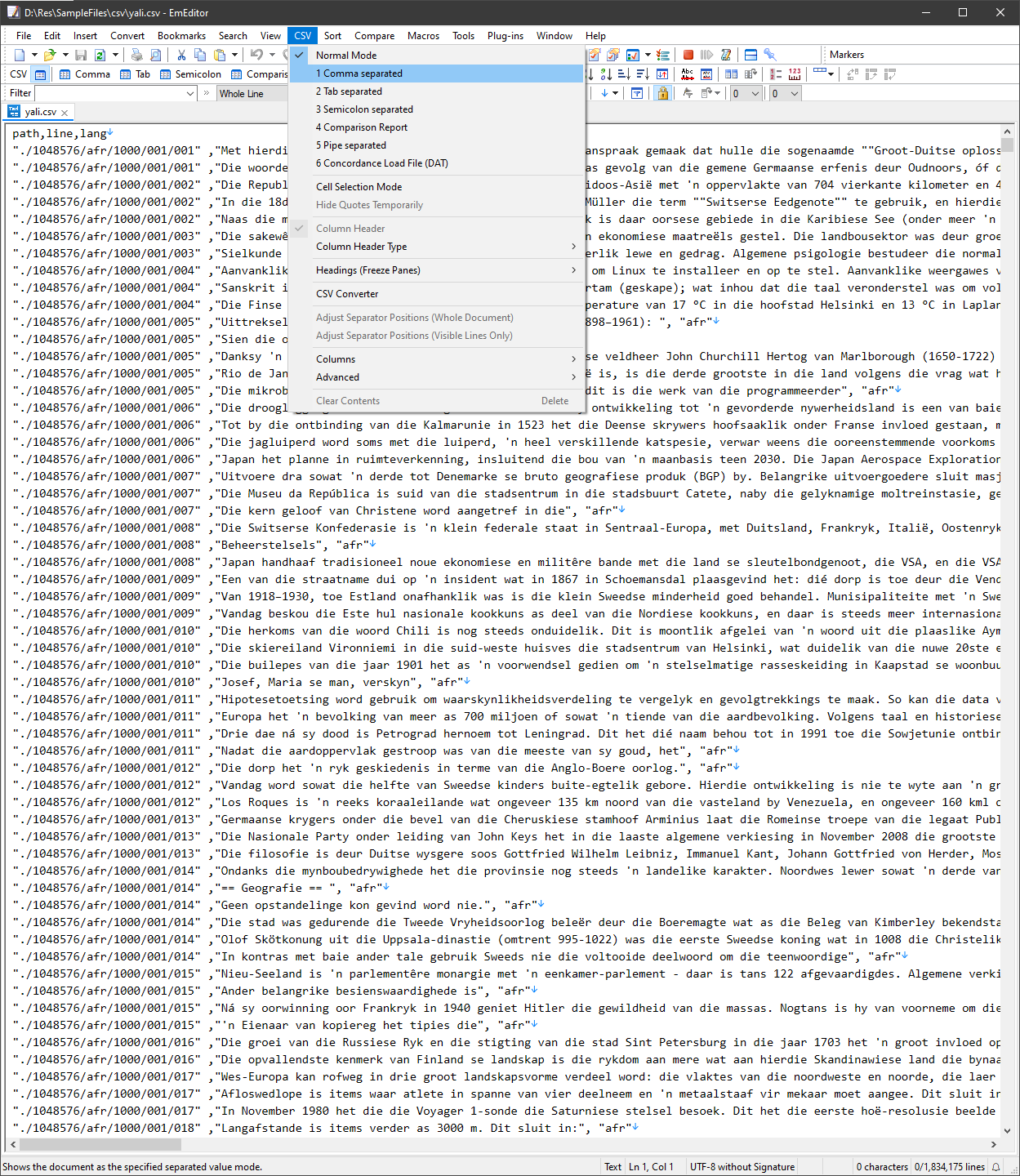
-
Choose a Delimiter: After loading your file, head to the 'CSV' menu and select the appropriate delimiter (e.g., comma, tab) to properly recognize and display your file in a structured CSV format rather than plain text. -
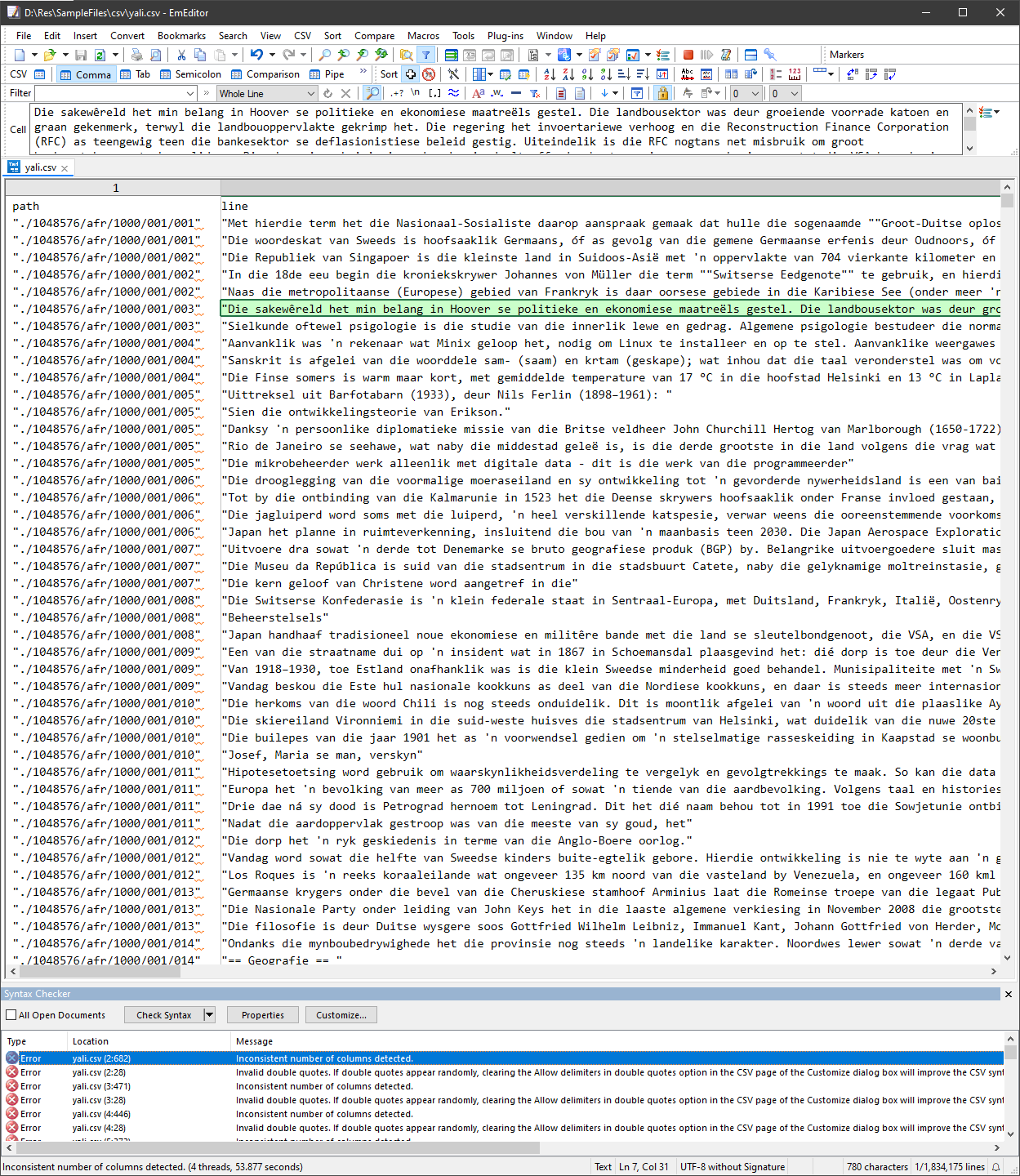
EmEditor handles large CSV files efficiently, and while advanced features like the Large File Controller are available in the paid version, it offers a 30-day free trial that provides robust capabilities for basic CSV management.
B. UltraEdit
UltraEdit is another strong option for large CSV files. It comes with useful features like column-mode editing and robust support for various delimiters. It can handle multi-gigabyte CSVs while preserving the file’s structure, which makes UltraEdit a reliable choice when you need to edit big csv files.
Step-by-Step Guide:
-
Getting Started: Get UltraEdit from its official website and launch it on your computer.
-
Open Your Large CSV File: Launch UltraEdit, then click 'File > Open', or drag and drop your large CSV file into the editor.
- Disable Temporary Files: When opening a file larger than 50 MB in UltraEdit, a warning dialog appears, prompting you to disable temporary files for better performance when handling large files.
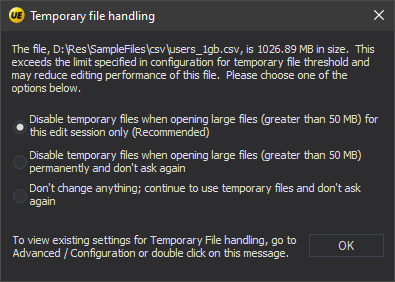
- Disable Temporary Files: When opening a file larger than 50 MB in UltraEdit, a warning dialog appears, prompting you to disable temporary files for better performance when handling large files.
-
UltraEdit CSV convert option: This option lets you quickly transform the character-separated text into fixed-width fields, ideal for managing large CSV files.
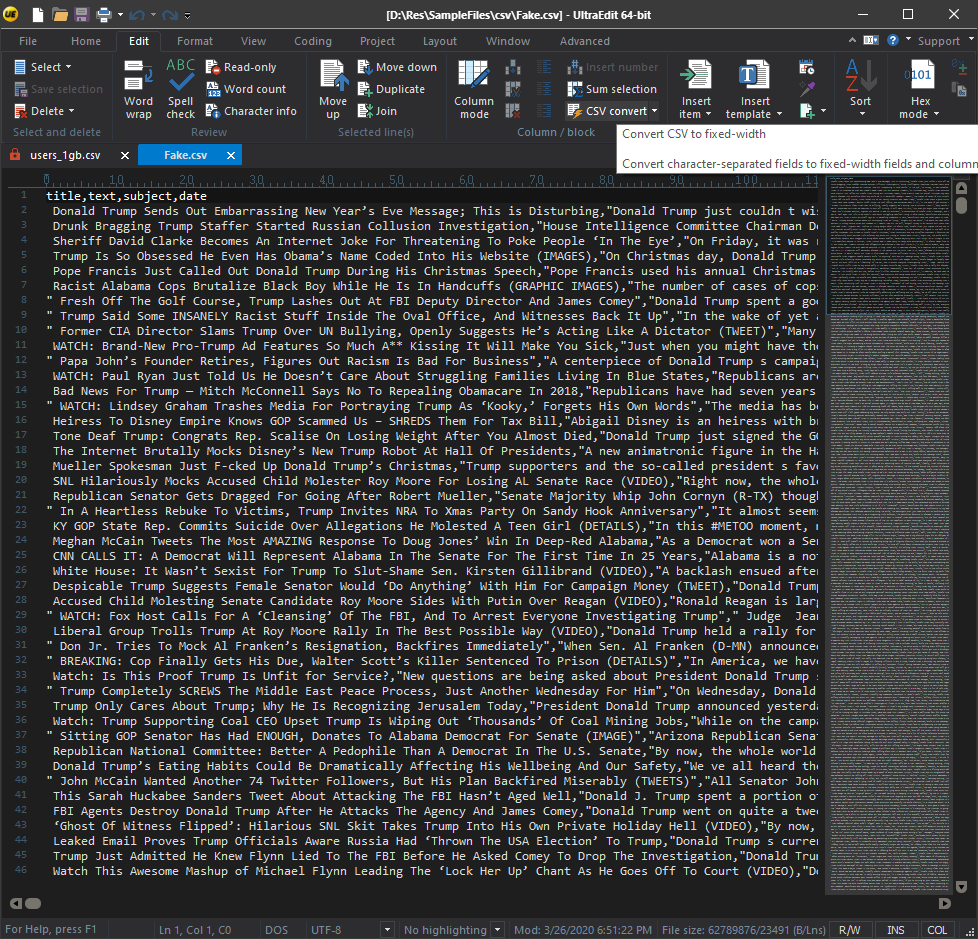
UltraEdit provides essential CSV handling features, such as column editing and basic data sorting. However, it lacks advanced capabilities like multi-level sorting or data merging, making it more suited as a general-purpose text editor rather than a specialized tool for complex CSV processing.
C. Large Text File Viewer
Large Text File Viewer is built to open massive CSV files quickly without consuming too much memory. It's perfect for viewing and searching large datasets with fair performance.
Step-by-Step Guide:
- Getting Started: Download the Large Text File Viewer and install the application following the on-screen instructions.
- Open and Navigate a Large CSV File:
- Click on the top left three-dot menu, then select 'App Command' to display the bottom toolbar.
- Use the 'Open File' button in the bottom right to select and open your large CSV file.
- The toolbar also offers additional tools for working with CSV files, such as navigating, sorting, and searching data.
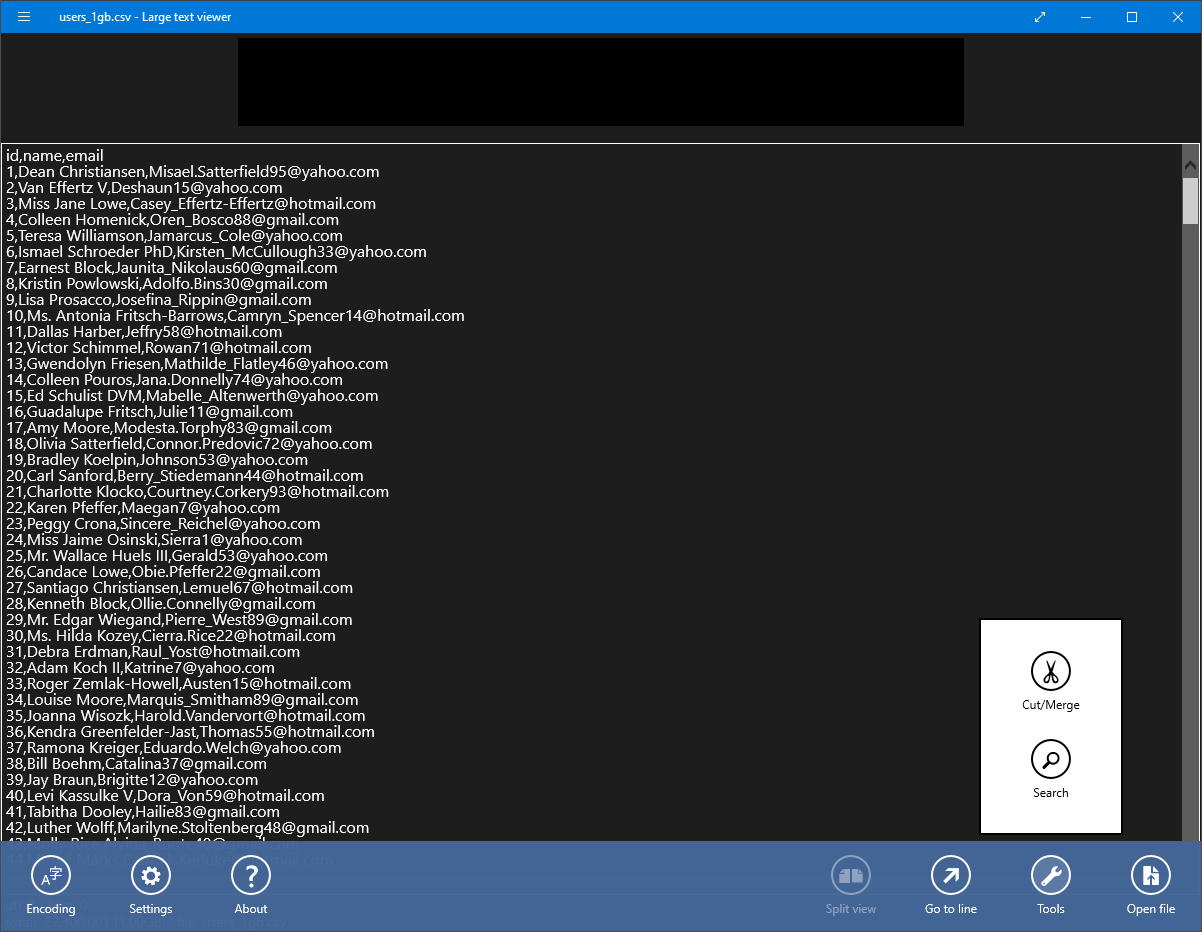
Large Text File Viewer loads fast, but don’t expect editing — it's read-only.
However, Text Editors aren't designed for deep data processing tasks. If you need features like complex sorting, joining, or data analysis, these tools may not be sufficient and might require switching to more specialized software, which we will explore in the following sections.
IV. Desktop Applications
Advanced desktop applications for CSV files offer quick access, filtering, and sorting for multi-gigabyte datasets without system slowdowns. They provide powerful, offline solutions that go beyond traditional spreadsheet tools, offering users refined data manipulation and efficient viewing.
A. Modern CSV
Modern CSV is a high-performance CSV editor for Windows that is optimized for handling large files. It offers powerful data manipulation features such as multi-cell editing, sorting, filtering, and batch editing, which makes it a solid choice for users who need both speed and advanced functionality.
Step-by-Step Guide:
-
Download and Install: Visit the Modern CSV download page and get the version suitable for your operating system.
-
Open Your CSV File: Launch the application and drag and drop your file or use 'File > Open' to load your dataset.
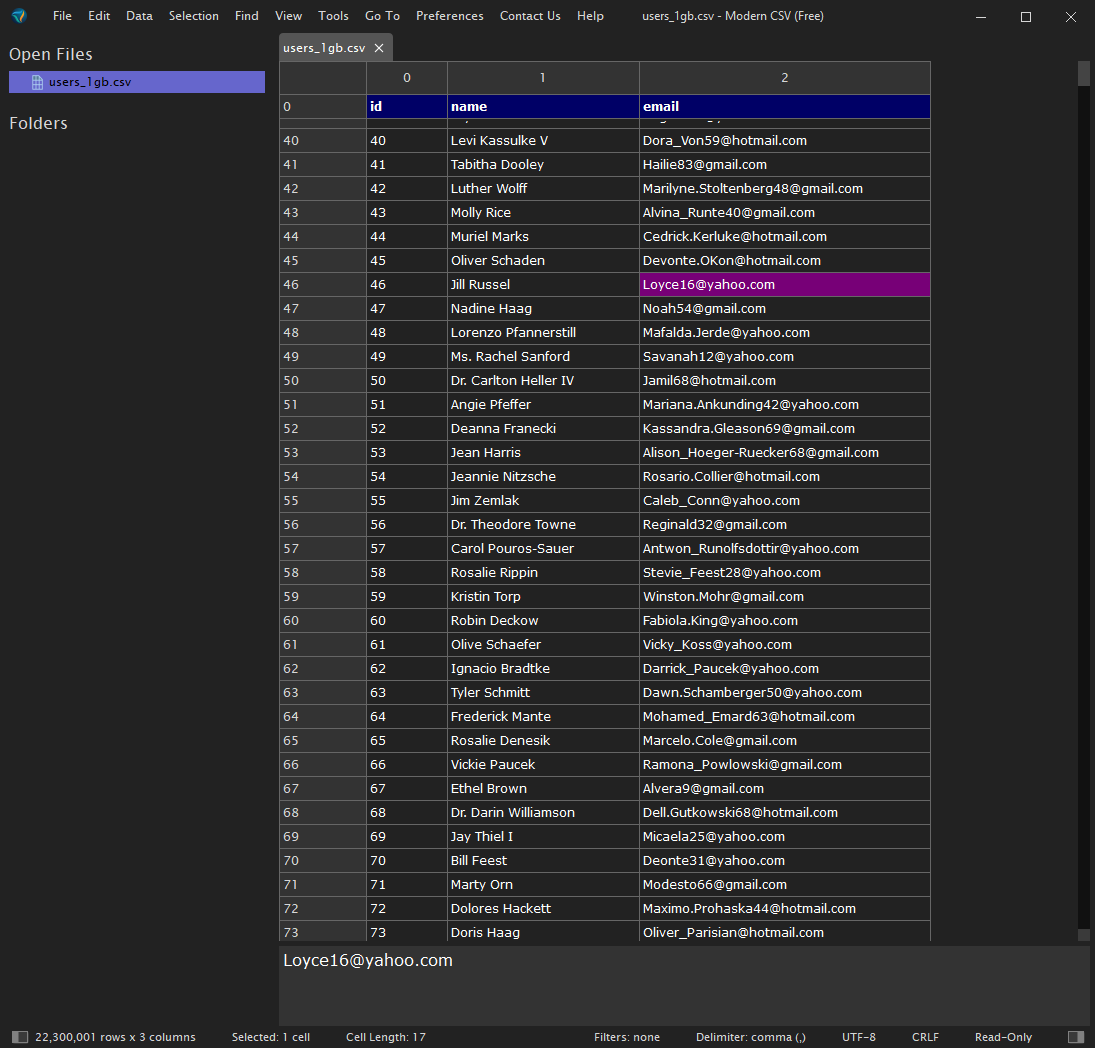
-
Navigate and Edit Data: Utilize features like search, filter, sort, and batch editing.
-
Data Manipulation:
- Filtering: Click on 'Data > Filter Rows' to filter data based on specific criteria.
- Sorting: Click on column headers to sort data ascending or descending.
However, the free version of 'Modern CSV' lacks features like filtering, data joining, and advanced editing, which are available only in the paid version.
B. OpenRefine
OpenRefine is a robust, open-source desktop tool designed for cleaning, transforming, and enriching large, messy datasets. It excels in handling complex data preparation tasks by offering powerful features like Filters and GREL for deep data transformations and consistency checks. Users can explore, clean, and filter their datasets based on specific criteria, and integrate external sources like Wikidata to augment the data.
Step-by-Step Guide:
-
Get Started: Get OpenRefine from its official website and launch it on your computer.
-
Start the application: Double-click 'openrefine.exe' on Windows or run the script on Mac/Linux, then your default web browser will open the OpenRefine interface.
-
Create a New Project:
- Click on 'Create Project'.
- Under 'Get data from', choose 'This Computer'.
- Click 'Choose Files' and select your CSV file.
- Click 'Next' to load your local CSV file and view it in OpenRefine's grid.
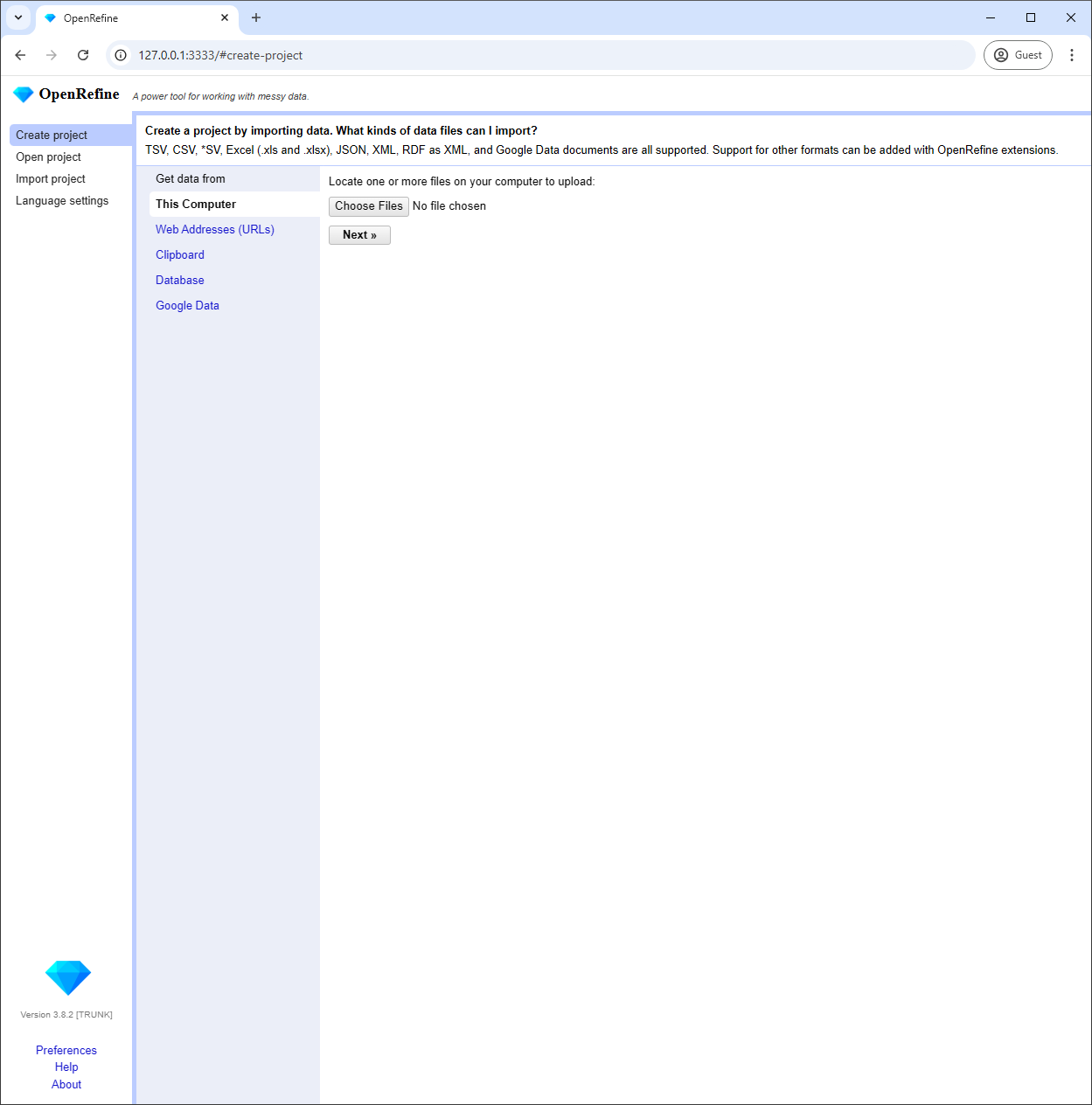
-
Explore and Clean Your Data:
- Adjust parsing options if necessary in the bottom options panel, for example, the character encoding and separator character.
- Use filters and other options to explore data.
- Perform transformations using built-in functions or GREL
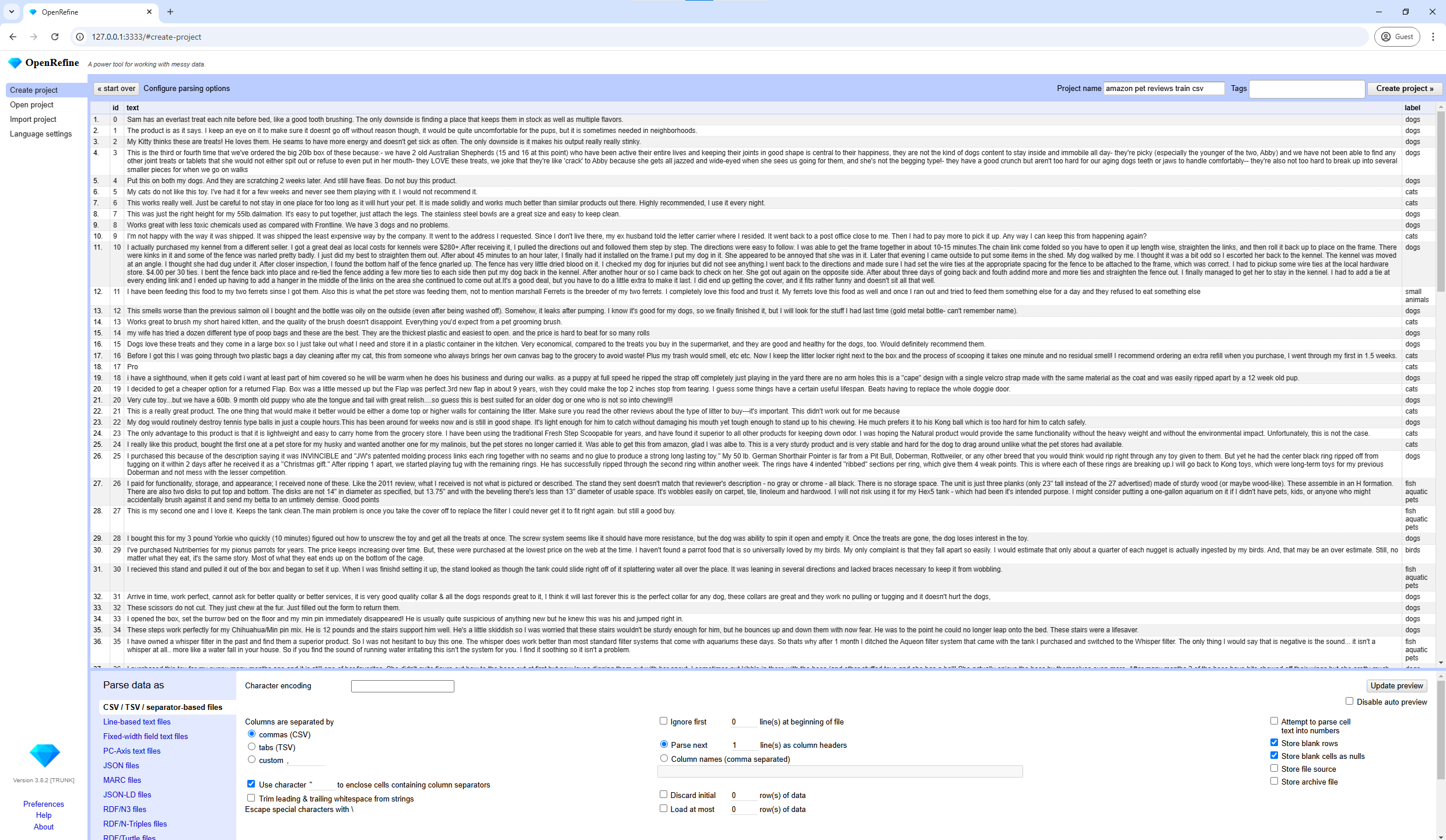
OpenRefine is a very powerful tool for cleaning and transforming messy CSV data. That said, it has a steep learning curve and no real-time collaboration, which can be drawbacks. Anyway, for those who do need robust on-premise data-cleaning capabilities, however, OpenRefine is still a solid choice.
C. Tad Viewer
Tad Viewer is a lightweight, free desktop application designed to view and filter large CSV files efficiently. Unlike more complex tools, Tad Viewer focuses on rapid display and filtering without the need to load entire datasets into memory, making it ideal for users who need quick access to large files without system slowdown.
However, it is a read-only tool, so if you need to edit or manipulate your data, you’ll need to use a more feature-rich tool. For basic analysis and lightweight filtering, Tad Viewer is a strong, no-cost option for handling large datasets efficiently.
Step-by-Step Guide:
- Download and Install: Head to the Tad Viewer website and download the appropriate version for your operating system (Windows, Mac, or Linux).
- Open Your CSV File: Launch Tad Viewer, click 'File > Open', or simply drag and drop your CSV file into the interface for quick access.
- Filter and Sort Data:
- Use the interface to filter rows and columns based on your criteria without requiring a full data load.
- Sort and organize data by clicking on the column headers, allowing for easy exploration.
- Utilize the bottom-left tools, such as 'Pivot', to perform aggregations and organize data hierarchically for deeper insights.
Even these powerful desktop applications have their limits. Some cost money (or have very limited free versions), and others lack advanced processing or editing features. For deeper analysis or collaborative work, you might need a more specialized tool.
V. CLI Tools
Below are three top CLI options for dealing with massive CSV files. Command-line tools provide a very efficient and flexible way to work with large CSV files. They can handle datasets too big for standard apps and use minimal memory, which makes them great for automation and heavy data processing.
A. CSVkit
CSVkit is a powerful suite of command-line tools built using Python for working efficiently with CSV files. CSVkit offers an array of utilities to view, convert, filter, and analyze CSV data directly from the terminal. It is a Python-based tool, so you need to have Python installed before working with it.
CSVkit offers versatile utilities such as csvcut for column selection, csvgrep for row filtering, csvsort for sorting, and csvstat for summary statistics. It excels in data conversion to formats like JSON and Excel, supports schema extraction by detecting column data types, and enables efficient data manipulation through SQL-like queries using csvsql.
Step-by-Step Guide:
-
Install
CSVkit:pip install csvkit -
Usage Examples:
-
View CSV Metadata: Get statistical summaries of your CSV:
csvstat large.csv -
Filter Rows: Extract rows where a column matches a specific value:
csvgrep -c "column_name" -m "value" large.csv > filtered.csv -
Select Columns: Extract specific columns:
csvcut -c "column1","column3" large.csv > selected_columns.csv -
Convert CSV to JSON: Convert your file to JSON:
csvjson large.csv > data.json -
Query CSV with SQL: Use SQL queries to manipulate CSV:
csvsql --query "SELECT column1, SUM(column2) FROM input GROUP BY column1" large.csv
-
CSVkit includes commands that can process data without loading the entire file into memory, such as csvcut and csvgrep. However, while it handles large files efficiently, certain operations may still require substantial memory, making it less practical for extremely large datasets.
B. AWK, sed, and grep
The classic Unix tools — AWK, sed, and grep — are essential for text processing and are widely used for large CSV files as well. These lightweight utilities enable flexible pattern matching, text substitution, and extraction without loading the entire file into memory. AWK, sed, and grep are lightweight tools pre-installed on most Unix/Linux systems, requiring no installation. They excel at stream processing by handling data line by line, which avoids high memory usage. Their powerful filtering capabilities allow for flexible pattern matching to extract or modify specific rows or fields directly from the command line.
Usage Examples:
-
Filter Rows with grep: Find lines containing a specific value:
grep "search_value" large.csv > filtered.csv -
Process Fields with
AWK: Perform operations on specific columns:awk -F',' '$3 > 100 { print $1, $2 }' large.csv > output.txt -
Edit Text with sed: Replace specific text patterns:
sed 's/old_value/new_value/g' large.csv > modified.csv
While AWK, sed, and grep can handle basic tasks like filtering and replacing text efficiently, handling CSV-specific issues such as quoted fields or embedded commas can be complex and may require advanced scripting expertise.
C. xsv
xsv is an extremely fast command-line CSV tool written in Rust. It processes data in a streaming fashion (instead of loading the entire file into memory), which means it can comfortably handle very large datasets with minimal RAM usage. Thanks to this design, xsv is a popular choice for working with huge files. It also supports handy features like indexing for quicker searches and provides various subcommands for tasks such as sampling rows, counting frequencies, and joining datasets.
Step-by-Step Guide:
-
Install
Cargo: If you don’t haveCargo(Rust’s package manager) installed, you can install it by following the instructions on the official Rust website or run this in your terminal; this will install the Rust toolchain, including Cargo.curl --proto '=https' --tlsv1.2 -sSf <https://sh.rustup.rs> | sh -
Install
xsv: Once you have Cargo installed, you can installxsvusing the following command:cargo install xsvAlternatively, you can download a binary from the releases page if you prefer not to install Rust and Cargo.
-
View CSV Headers: Display column headers:
xsv headers large.csv -
Sample Rows: Extract a random sample of rows:
xsv sample 100 large.csv > sample.csv -
Select Columns: Extract specific columns:
xsv select column1,column3 large.csv > selected_columns.csv -
Sort Data: Sort the file based on a specific column:
xsv sort -s column2 large.csv > sorted.csv -
Join CSV Files: Perform a join operation between two CSV files:
xsv join column_id file1.csv column_id file2.csv > joined.csv
xsv is very fast and memory-efficient, but its scope is limited to common CSV operations. For complex transformations or multi-level joins, more sophisticated tools may be needed.
Command-line tools are effective for opening large CSV files, but handling huge files can still be resource-intensive and may hit system limits. Besides, for those unfamiliar with terminal commands, these tools may not fully replace the convenience of traditional spreadsheets.
VI. Databases
When dealing with huge CSV files that are too big to open any other way, databases offer a powerful alternative. By importing large CSV datasets into a database, you can efficiently query, manipulate, and view your data without hitting system memory limits or any tool’s size limit. Below, we explore three popular databases — SQLite, MySQL, and PostgreSQL — that excel at handling big CSV files.
GUI Tools for Easy Database Interaction
You can utilize graphical clients to simplify working with databases. They offer user-friendly interfaces for importing, querying, and visualizing your data.
Multi-Database Clients:
Specific Database Clients:
- MySQL Workbench: Official MySQL GUI
- pgAdmin: Official PostgreSQL GUI tool
However, for simplicity and to keep things straightforward, we will proceed with using the CLI and services of the databases directly in the following guides.
A. SQLite
SQLite is a lightweight, file-based database system that lets you open and query large CSV files without needing a server setup. It's an ideal choice for quickly working with big datasets, thanks to its standard SQL support and efficient data handling, all within a single local file.
Step-by-Step Guide:
-
Install SQLite:
-
On Windows: Download the SQLite Tools for Windows from the SQLite Download page (look for
sqlite-tools-win32-x86-*.zip) and extract the files to a directory of your choice. -
On macOS, SQLite comes pre-installed. Verify by typing:
sqlite3 --versionIf not installed, use Homebrew:
brew install sqlite -
Linux: Install via your distribution's package manager. For Ubuntu/Debian:
sudo apt-get install sqlite3
-
-
Import CSV into SQLite: To open and query large CSV files using SQLite, check out our blog post covering both GUI-based and command-line methods for a visual or direct approach.
SQLite is excellent for managing large CSV files simply and efficiently. However, it does not support concurrent writes and struggles with massive file sizes, making it less ideal for high-throughput or transactional tasks. For better concurrency and performance with large CSV datasets, server-based databases like PostgreSQL and MySQL are more suitable.
B. MySQL
MySQL is a powerful, server-based relational database designed to handle large CSV files with ease. It offers high performance, making it ideal for complex queries and data manipulations. With its scalability, MySQL is suitable for both small and enterprise-level applications, providing comprehensive SQL support for advanced querying and data analysis.
Step-by-Step Guide:
-
Install MySQL Server: Download the MySQL Community Server from the official website.
-
Start the MySQL Server:
-
Windows: MySQL runs as a service after installation.
-
macOS: If installed via Homebrew:
brew services start mysql -
Linux
sudo service mysql startor
sudo systemctl start mysql
-
-
Log In to the MySQL Command-Line Interface (on Windows Command Prompt):
mysql -u root -pEnter your root password when prompted.
-
Create a Database:
CREATE DATABASE mydatabase; USE mydatabase; -
Create a Table Matching Your CSV Structure:
CREATE TABLE mytable ( column1 VARCHAR(255), column2 INT, column3 FLOAT );Adjust the column names and data types to match your CSV file.
-
Prepare for Import:
- Ensure the CSV file is accessible by the MySQL server. For Windows, place the CSV file in a directory like
C:\ProgramData\MySQL\MySQL Server 8.0\Uploads\. - Update the MySQL configuration file (
my.ini) to setsecure_file_privto the directory containing your CSV file.
- Ensure the CSV file is accessible by the MySQL server. For Windows, place the CSV file in a directory like
-
Import Data:
LOAD DATA INFILE 'C:/ProgramData/MySQL/MySQL Server 8.0/Uploads/large.csv' INTO TABLE mytable FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n' IGNORE 1 ROWS;If you encounter a "secure-file-priv" error, you can use
LOAD DATA LOCAL INFILE:mysql -u root -p --local-infile=1Then, in the MySQL prompt:
SET GLOBAL local_infile = 1; LOAD DATA LOCAL INFILE 'C:/path/to/large.csv' INTO TABLE mytable FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n' IGNORE 1 ROWS;
- Query Your Data:
SELECT column1, SUM(column2) FROM mytable GROUP BY column1;
This lets you process and view big CSV data efficiently.
MySQL is a robust tool for handling large CSV files, but you'll need to set up a server and manage file permissions for imports.
C. PostgreSQL
PostgreSQL is a powerful database for importing large CSV files efficiently, thanks to its optimized COPY command. The COPY command offers high performance for bulk data imports, along with the flexibility to handle various delimiters, quote characters, and null value options, making it a versatile choice for managing CSV files.
Step-by-Step Guide:
-
Getting started: Download and install PostgreSQL from the official website.
-
Start the PostgreSQL Service:
-
Linux:
sudo service postgresql start -
Windows: Open the 'Services' application, find 'PostgreSQL' in the list, right-click, and select 'Start'.
-
Mac (with Homebrew):
brew services start postgresql
-
-
Log in to PostgreSQL CLI:
-
Open the psql, PostgreSQL CLI:
psql -U username -d database -
If connecting to the default database:
psql -U postgres
-
-
Prepare the Database and Table:
-
Create a Database and connect to it:
CREATE DATABASE mydatabase; \c mydatabase; -
Create a Table:
CREATE TABLE mytable ( column1 VARCHAR(255), column2 INT, column3 FLOAT );
-
-
Import CSV File Using
COPYcommand:COPY mytable FROM '/path/to/large.csv' DELIMITER ',' CSV HEADER;Ensure the file path is accessible by the PostgreSQL server. If importing from the client machine, use:
\COPY mytable FROM '/path/to/large.csv' DELIMITER ',' CSV HEADER; -
Query Your Data:
SELECT * FROM mytable WHERE column2 > 1000;
While PostgreSQL is a powerful option for handling large CSV files, it requires server setup and configuration, making it less ideal for quick tasks.
Using PostgreSQL, you can analyze working with large CSV datasets like NYC Taxi trip data, as demonstrated in this example on GitHub.
Database setups can be complex, especially with server-based solutions like MySQL and PostgreSQL, which require configuration and permissions. On the other hand, SQLite is simpler but has its limitations. Despite this, databases are highly effective for large-scale CSV data processing.
VII. Programming Languages
Programming languages and their libraries allow you to build adaptable solutions tailored to your precise requirements, especially when handling complex data transformations or integrating with other systems. Below, we explore three programming languages — Python, R, and Go — that can be used to handle large CSV datasets efficiently.
A. Python
Python is a versatile programming language renowned for its robust data processing capabilities. It offers powerful libraries to open and analyze large CSV files, even those too big for memory.
We'll begin with Pandas and Dask for CSV data manipulation, exploration, and joining datasets. Then, we'll introduce the Jupyter Notebook for interactive exploration.
Install Python: Before you proceed with installing libraries like Pandas and Dask, ensure that Python is installed on your system. You can download Python from the official Python website.
I. Pandas: a powerful data manipulation library with data structures like DataFrames for handling structured data.
-
Install Pandas
pip install pandas -
Read and process the CSV file in smaller chunks, to manage memory usage:
import pandas as pd chunk_size = 100000 # the number of rows to read per chunk chunks = [] for chunk in pd.read_csv('large.csv', chunksize=chunk_size): # Perform data processing on each chunk filtered_chunk = chunk[chunk['column_name'] > 100] chunks.append(filtered_chunk) # Combine processed chunks into a single DataFrame result = pd.concat(chunks) -
However, Pandas loads data into memory, so when working with large CSV files that exceed your system's RAM, Pandas alone may not be able to handle them. You can read and process data in smaller chunks, which helps manage memory usage, but this approach may not be suitable for all types of analyses.
II. Dask: a flexible library for parallel computing in Python, that is specifically designed for out-of-core computation, allowing you to work with datasets larger than your system's memory. Dask provides a familiar DataFrame API that integrates seamlessly with Pandas but handles data in a way that distributes computations across multiple cores and manages memory efficiently.
-
Install
Dask:pip install dask -
Read and Process Large CSV Files with
Dask:import dask.dataframe as dd # Read the large CSV file into a Dask DataFrame df = dd.read_csv('large.csv') # Filter the DataFrame based on a condition filtered_df = df[df['column_name'] > 100] # Compute the result, triggering the actual execution of the lazy operations result = filtered_df.compute()
B. R
R is designed for statistical computing and graphics, so it’s very effective at handling and analyzing large datasets (including big CSV files). With its high-performance data manipulation packages and advanced statistical analysis and visualization tools, R has become a go-to choice for data scientists working with big data.
Step-by-Step Guide:
-
Install R and RStudio:
- Download
Rfrom CRAN. - Install RStudio — a user-friendly IDE for
R— from the official website.
- Download
-
Use the
data.tablePackage to Read Large CSV Files:The
data.tablepackage provides high-performance data manipulation capabilities, making it ideal for working with big CSV files.
-
Installation: In R or RStudio, install the
data.tablepackage by running:install.packages("data.table") -
Usage:
library(data.table) # Read large CSV file efficiently dt <- fread("large.csv") # Perform data operations result <- dt[column2 > 1000, .(Total = sum(column3)), by = column1]
The fread() function in the data.table package offers significant advantages over base R functions when working with large CSV files. One key benefit is speed, as fread() is much faster at reading large datasets compared to base R functions. Additionally, it is highly memory-efficient, designed to handle big CSV files without consuming excessive amounts of memory, making it an optimal choice for processing large-scale data in R.
- Use the
readrpackage to parse large CSV files:-
The
readrpackage is part of the tidyverse and provides a fast and friendly way to read rectangular data, offering quicker parsing of large CSV files compared to base R functions. -
Installation:
install.packages("readr") -
Usage:
library(readr) library(dplyr) # For data manipulation # Read large CSV file efficiently df <- read_csv("large.csv") # Perform data operations using dplyr result <- df %>% filter(column2 > 1000) %>% group_by(column1) %>% summarize(Total = sum(column3))
-
The read_csv() function from the readr package offers several advantages over base R’s read.csv(). In terms of performance, read_csv() is notably faster when reading large CSV files. Additionally, it provides a consistent and user-friendly interface for data import and manipulation, especially when used in conjunction with other tidyverse packages like dplyr, enhancing ease of use and workflow efficiency.
R programming language is effective for handling and analyzing large datasets when using optimized packages like data.table. However, working with datasets larger than available memory may require additional strategies or tools.
Technical Strategies to Process Big CSV Files
Very large CSV files can push your system to its limits. Fortunately, using some best practices will improve performance, avoid crashes, and make data processing smoother. In this section, we’ll explore a few technical strategies to handle large datasets more efficiently.
1. Use A Sample of your CSV data
When dealing with big CSV files, it's practical to work with a representative sample of your entire data during development and testing. Sampling reduces resource use and speeds up iterations.
Example: Use the default Linux head command to extract the first 1,000 lines.
head -n 1000 large_dataset.csv > sample.csv
2. Split Large CSV Files into Smaller Chunks
Splitting a big CSV file into smaller, more manageable parts can help you bypass the limitations of tools and streamline processing.
Example: Run split to break the file into 1,000,000‑line chunks.
split -l 1000000 large_dataset.csv chunk_
This command creates multiple files with the prefix chunk_, making it easier to open CSV files that were previously too big to handle.
3. Compress CSV Files to Reduce Size
Compressing large CSV files saves storage and speeds transfers.
Example: Compress the file with gzip. The result, large_dataset.csv.gz, is much smaller.
gzip large_dataset.csv
Many tools and libraries read compressed CSVs directly. For example, Python’s Pandas reads gzip‑compressed CSVs out of the box.
import pandas as pd
df = pd.read_csv('large_dataset.csv.gz', compression='gzip')
4. Convert CSV to Optimized Formats Like Parquet
Convert CSV files to a columnar format such as Parquet. Parquet files are optimized for query performance and are more efficient to open and process when dealing with large datasets.
Example: You can use Python to convert a CSV file to Parquet format.
import pandas as pd
df = pd.read_csv('large_dataset.csv')
df.to_parquet('large_dataset.parquet')
5. Process Data in Chunks
If a CSV file is too big to fit in memory, processing it in chunks can prevent system overload.
Example: Use Pandas to read and process a large CSV file in chunks.
import pandas as pd
chunk_size = 100000
for chunk in pd.read_csv('large_dataset.csv', chunksize=chunk_size):
# Process each chunk
process(chunk)
6. Speed Up File Loading with Memory Mapping
Memory mapping enables faster file I/O operations by treating file data as if it were in memory, which is beneficial for large CSV files.
Example: You can use Python's mmap module as follows:
import mmap
with open('large_dataset.csv', 'r') as f:
with mmap.mmap(f.fileno(), length=0, access=mmap.ACCESS_READ) as mm:
for line in iter(mm.readline, b''):
process(line.decode('utf-8'))
7. Parallel Processing to Handle More Data at Once
Utilizing multiple CPU cores can accelerate the processing of large CSV files.
Example: Using Python's multiprocessing library.
import pandas as pd
from multiprocessing import Pool
def process_chunk(chunk):
# Process the chunk
return result
if __name__ == '__main__':
chunk_size = 100000
with Pool() as pool:
results = pool.map(process_chunk, pd.read_csv('large_dataset.csv', chunksize=chunk_size))
8. Stream Data for Real-Time Processing
For applications requiring real-time data processing, streaming data directly can be more efficient than batch processing.
Example: Using a generator to read and process data line by line:
def read_large_file(file_path):
with open(file_path, 'r') as file:
for line in file:
yield line
for line in read_large_file('large_dataset.csv'):
process(line)
FAQ
- What is the maximum size for a CSV file? Technically, there’s no fixed maximum size for a CSV itself – you can make a CSV as large as you want. The real limits come from your hardware and software. In practice, how big a CSV you can open depends on your computer’s memory/CPU and the application you’re using. Every program has its point at which it might slow down or crash; that threshold varies by software and your system setup.
- How can I open a big CSV file without crashing my computer? Applications like Tad Viewer or Large Text File Viewer can open big CSV files without loading the entire content into memory. If that doesn't work, you can read and process the file in smaller sections using programming languages like Python.
- How to open CSV file with more than 1 million rows? Excel's Power Query can import data into the Data Model, bypassing Excel’s 1 million row limit. Divide the CSV file into smaller chunks that Excel can handle. Consider tools like LibreOffice Calc or dedicated CSV editors that handle larger files better.
- What are Excel's size limits? Excel has a hard limit of about 1,048,576 rows and 16,384 columns, so anything beyond that won’t open fully. Even below those limits, a very large CSV can use up all your available memory and make Excel slow or unresponsive. In short, Excel isn’t designed for extremely large datasets ��— it will struggle once the file size gets too big.
- How can I open a large CSV file in Access? Access can import CSV files through its wizard, but keep in mind the 2 GB database size limit. Import only the necessary columns or rows to stay within size constraints.
- What's the best way to open a CSV file containing more than a billion rows? Utilize cloud-based data warehouses like Google BigQuery, Amazon Redshift, or Azure Synapse Analytics, designed for massive datasets. You can also use frameworks like Apache Spark or Hadoop for the distributed processing of large-scale data.
- How can I run SQL queries on a large CSV file without importing it into a database? Command-line Tools like
CSVkitallow SQL-like queries directly on CSV files without a full database setup. - How can I open a large CSV file on a computer with limited resources? Work with a subset of the data to reduce resource consumption. Remove unnecessary columns or compress the file if possible. Employ cloud services that handle processing remotely, reducing the load on your local machine.
- What is the difference between CSV and Excel formats (
.xlsor.xlsx)? CSV files are plain text files where data is separated by commas, making them simple and widely compatible for data exchange. Excel files are proprietary formats used by Microsoft Excel that can store complex data with formatting, formulas, and macros. CSV is ideal for basic data storage and transfer, while Excel offers advanced features for data manipulation and visualization within the spreadsheet software. You can always export your Excel files into CSV to open them with all the appropriate tools we mentioned in this guide. - What are other variations of the CSV file format? Tab-Separated Values (TSV), Pipe-Separated Values (PSV), Space-Separated Values (SSV), Delimiter-separated Values (DSV) with custom delimiters.
Key Takeaways
When you need to work with large CSV files:
Know the Limits
- Ensure your computer has sufficient RAM and CPU power to handle large CSV files.
- Consider cloud-based solutions if your local hardware isn't adequate.
- Recognize limitations of tools like Excel's size limit.
- Be prepared to switch to more capable alternatives when necessary.
Choose the Right Tool
- Excel with Power Query and LibreOffice Calc can handle big CSV files, but may struggle with moderately large CSV datasets.
- EmEditor and UltraEdit open large CSV files quickly but might lack advanced data manipulation features.
- SQLite, MySQL, or PostgreSQL efficiently manage large datasets with powerful querying capabilities, but require setup and SQL knowledge.
Python(with libraries likePandas,Dask) andRoffer great flexibility for advanced data processing but demand programming skills.CSVkitandxsvprovide quick processing of big CSV files but may have a steeper learning curve for those unfamiliar with command-line interfaces.
Implement Best Practices
- Process data in chunks to manage memory usage and prevent system overloads.
- Compress CSV files or convert them to optimized formats like Parquet to improve performance and reduce storage needs.
- Utilize parallel processing by leveraging multiple CPU cores to speed up data processing tasks.
Explore Ideas
- Combine different tools and methods to fit your needs.
- If spreadsheets can't handle your file size, try specialized CSV tools or text editors.
- For complex data manipulation, use databases or programming languages.
In practice, no single tool will handle every scenario perfectly — sometimes you’ll use one to compensate for the limits of another. Managing large CSV files effectively is about matching the right tools and strategies to your specific needs. By combining approaches thoughtfully, you can tame even very large datasets and extract meaningful insights from them. Happy CSV exploring!